ML

ML
WisdomX机器学习
监督学习
回归
线性回归、多项式回归
分类
例如:肿瘤预测
无监督学习
聚类
例如:相似新闻、根据dna阵列进行分类、用户分类
异常检测
例如:欺诈检测
降维
对大数据集进行降维
线性回归
f(x)=wx+b
逻辑回归
0或1
sigmoid函数:
$$
g(z)=\frac{1}{1 + e^{-z}}
$$
loss:
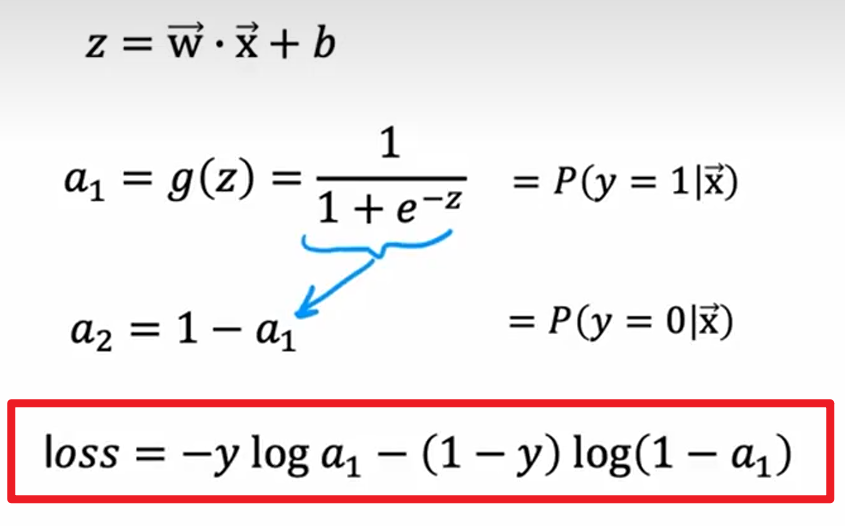
决策边界
Softmax回归
- 用于多分类
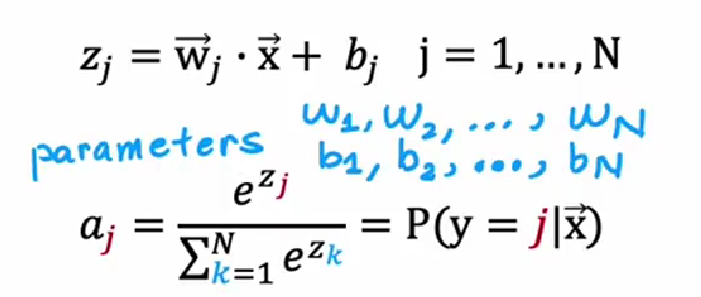
loss:

多标签分类
优化算法(优化loss到最小值)
梯度下降
全局统一的学习率
Adam(自适应距离估计)
每个参数一个学习率
自动调节学习率
迁移学习
用一个已经训练好的网络,保留所有参数,更换输出层,以下两种方式训练微调:
option1、重新训练最后一层的参数
option2、重新训练所有参数
优点:不用监督进行预训练
部署模型
部署模型到推理服务器上,之后通过api调用的方式使用模型
误差指标(处理类别不平衡和稀有类别)
精确率
=该类别预测正确数/预测该类别数
召回率
=该类别预测正确数/实际该类别数
权衡
手动设置阈值
自动设置阈值
F1 score 调和平均数
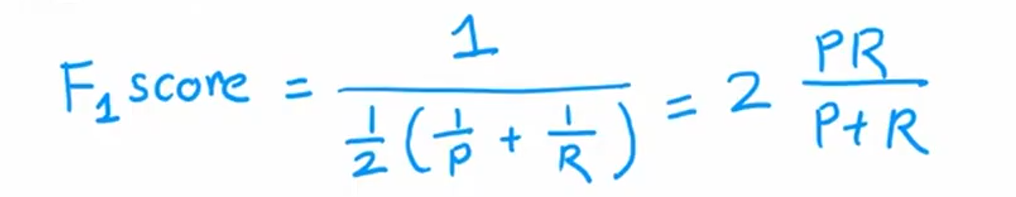
决策树
样子

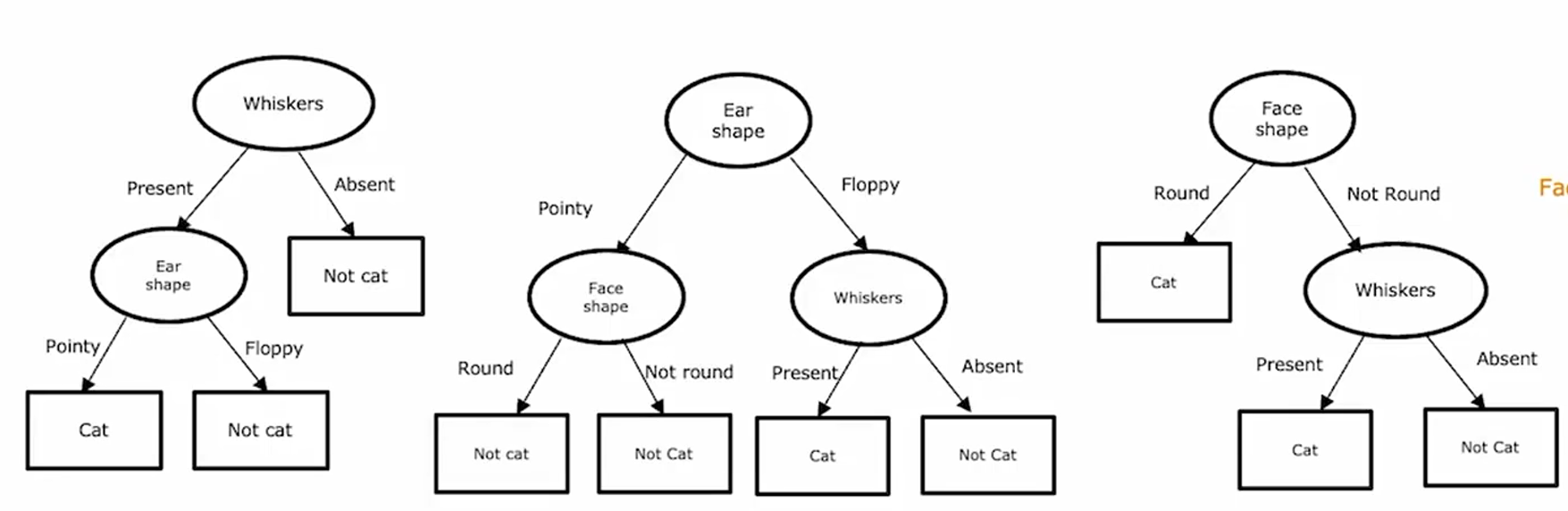
构建
如何选择特征作为节点?
最大化纯度或最小化不纯度
什么时候停止分裂?
- 当一个node上全为一类
- 达到最大深度
- 当纯度分数上的改进低于阈值
- 当一个node上的数量低于阈值
步骤

量化纯度
熵函数测量不纯度
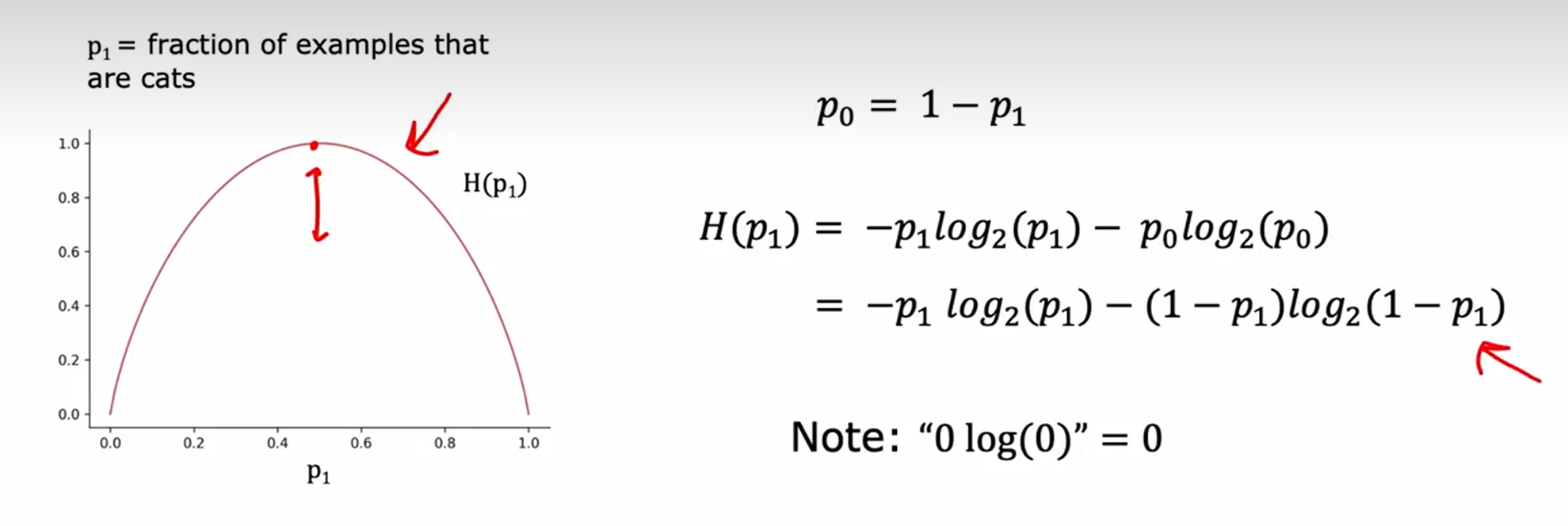
信息增益
计算并根据此判断如何分割
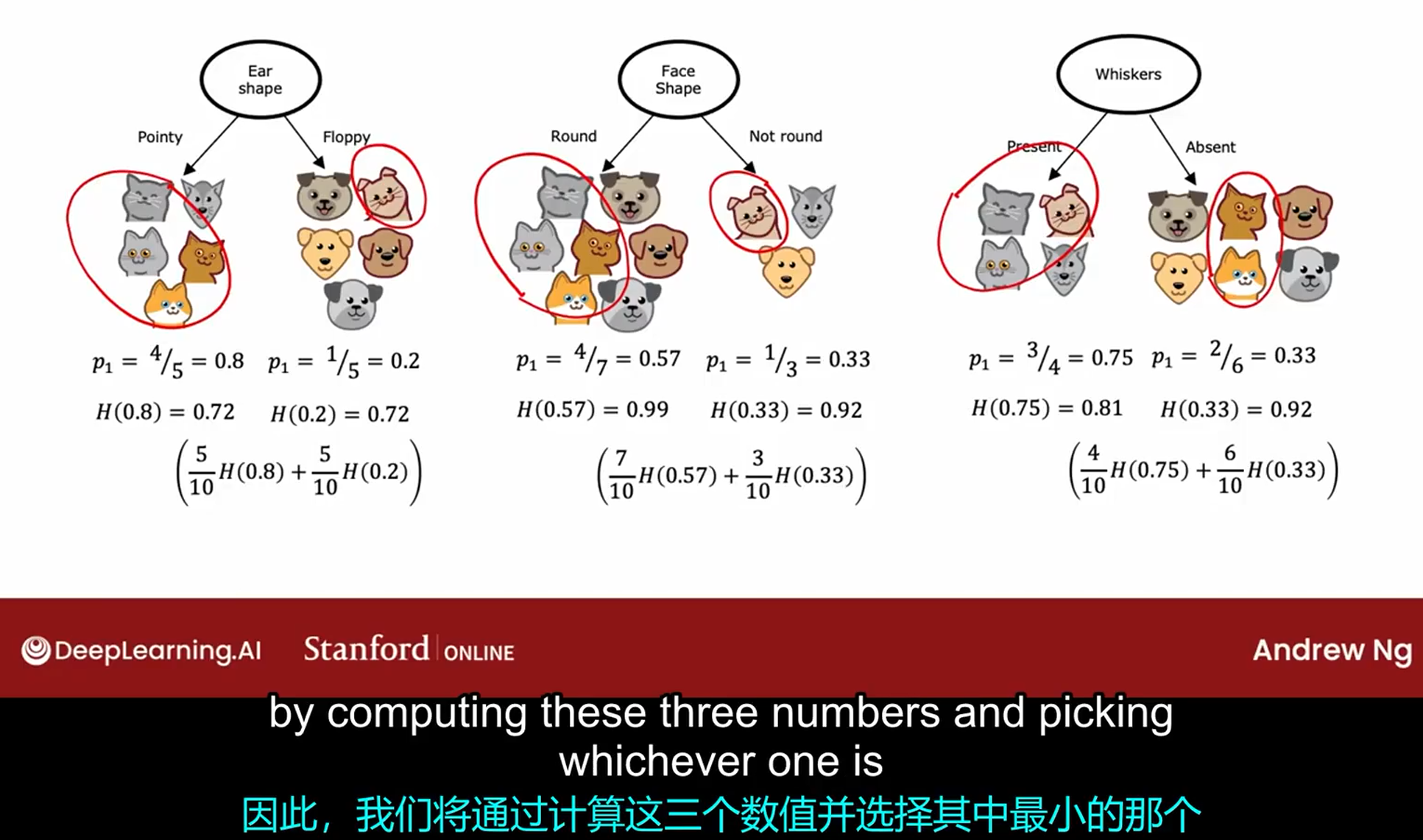
要最大的熵的减少量

特点
- 结构化数据(非结构化数据:图像、视频、音频、文本,一般用神经网络)
- 快
- 小型决策树可解释
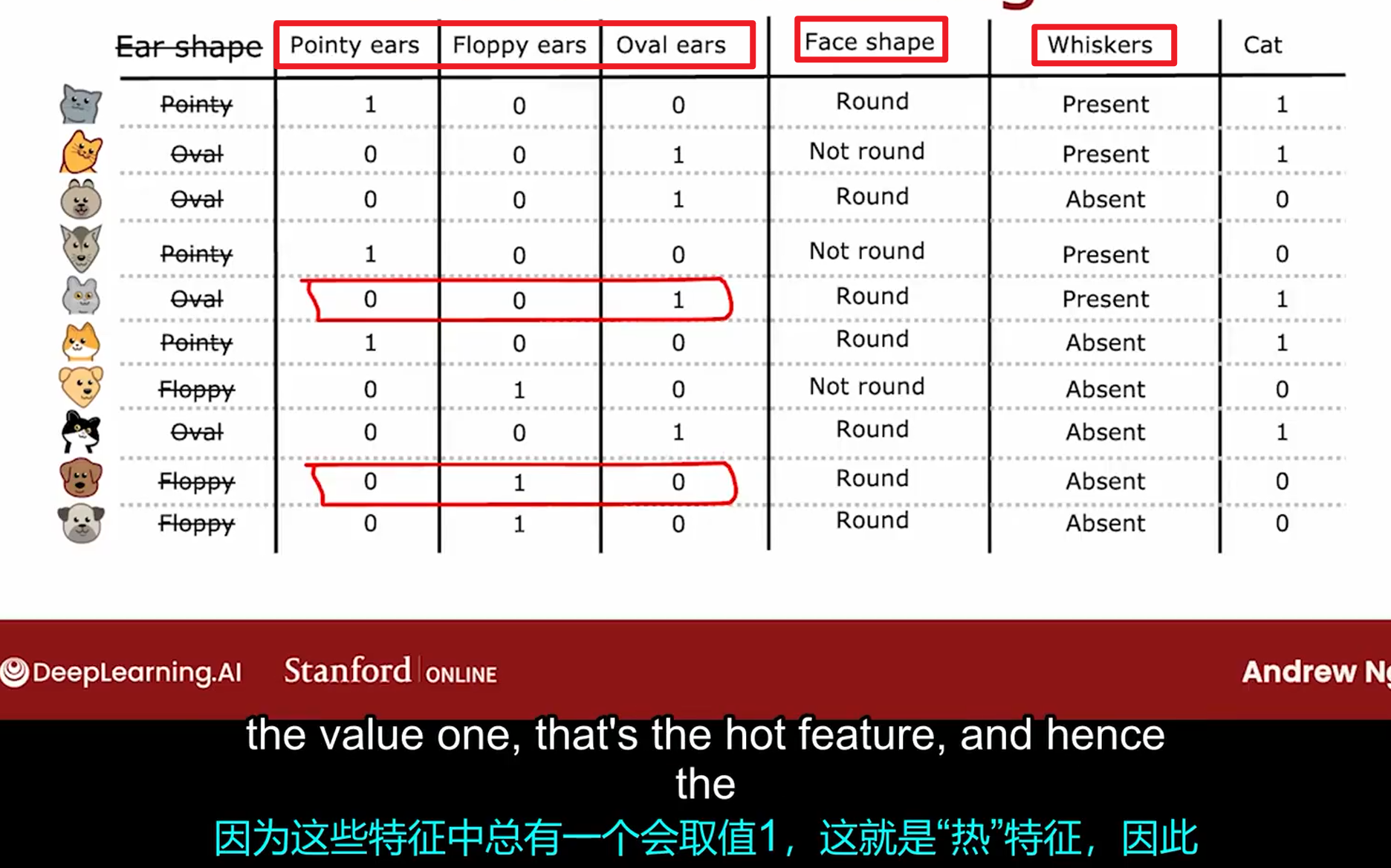
离散值:独热编码
one hot encoding
当一个特征的取值大于2个时
连续值
考虑不同的分隔值,根据信息增益进行判断
回归树
在决策树的基础上根据最大的方差减少量进行构建
多决策树
样子
单一决策树对训练数据的变化很敏感,所以要多决策树
用多个决策树对样本进行分类,最后每个tree进行投票决定最终结果
构建
用有放回采样构建多个随机训练集
随机森林
在多决策树的基础上进行优化:在每个节点中,从所有特征中选择k个特征的子集,从该子集中挑选信息增益最高的特征作为分裂选择,通常k=n^(1/2)
XGBoost
Boost:在前几次采样中随机选择,后面的采样就会更可能选择之前的树里面表现不好的样本
XGBoost:为不同的训练样本分配不同的权重

无监督学习
聚类
无标签
k均值
- 随机猜测聚类中心位置
- 将每个点与一个聚类进行关联
- 将聚类中心移动到聚类点的平均位置
- 重复2和3直到中心位置不再变化
聚类中心与点的距离:
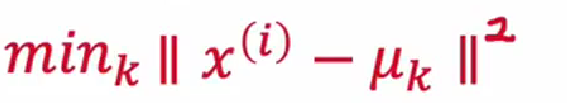
- loss
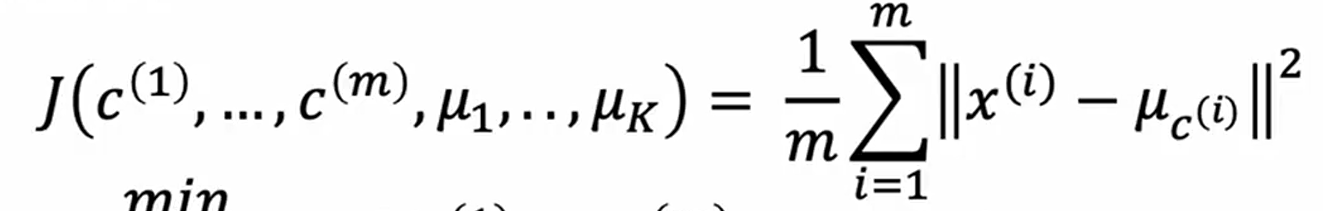
聚类中心初始化为随机k个点的位置
多次运行k均值,找到最小loss的那批
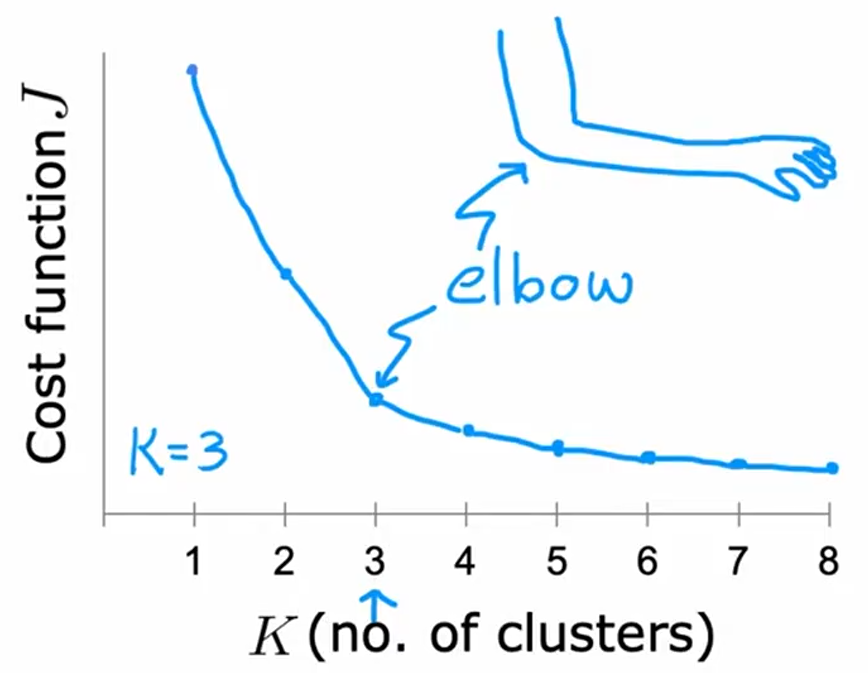
如何选择k?
ELBO:

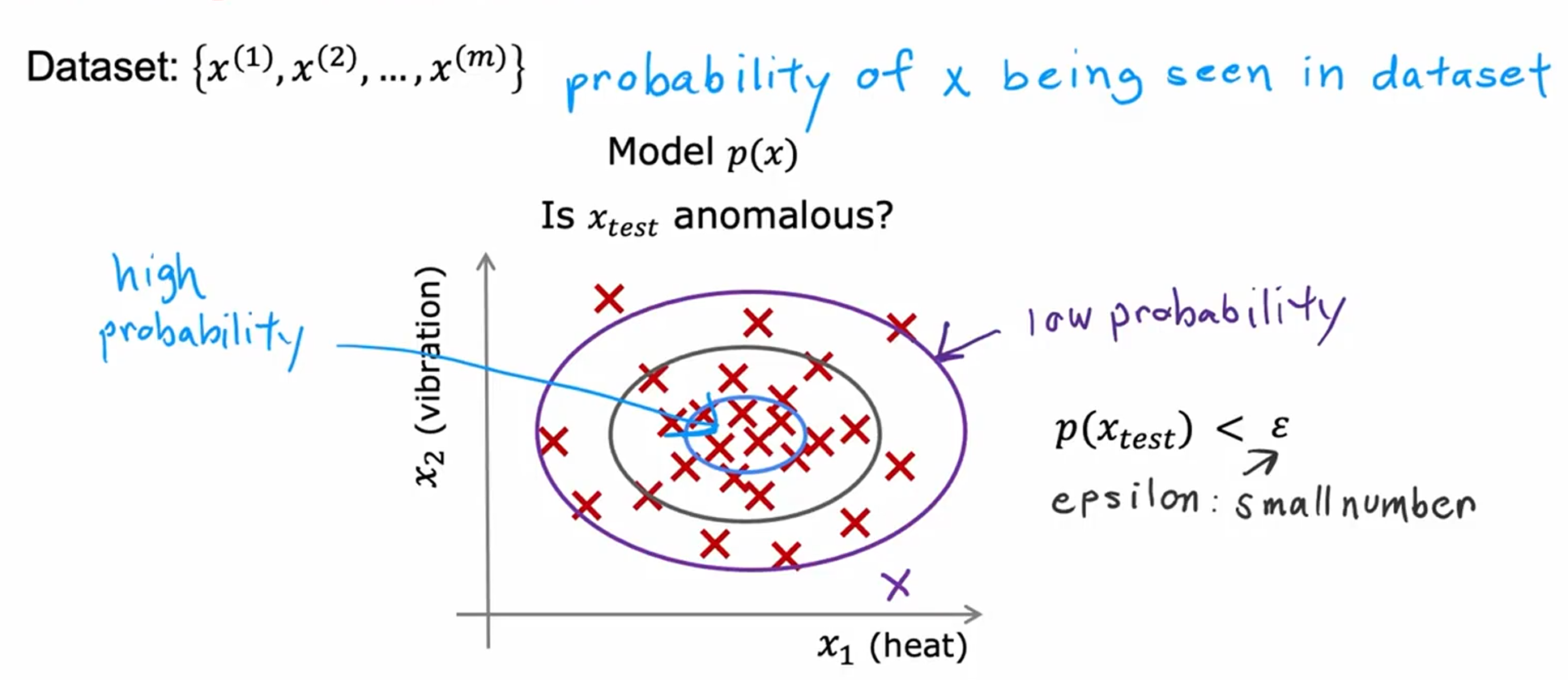
异常检测
当特征值的概率p小于一个阈值时,这可能有异常
正态分布
一个特征:
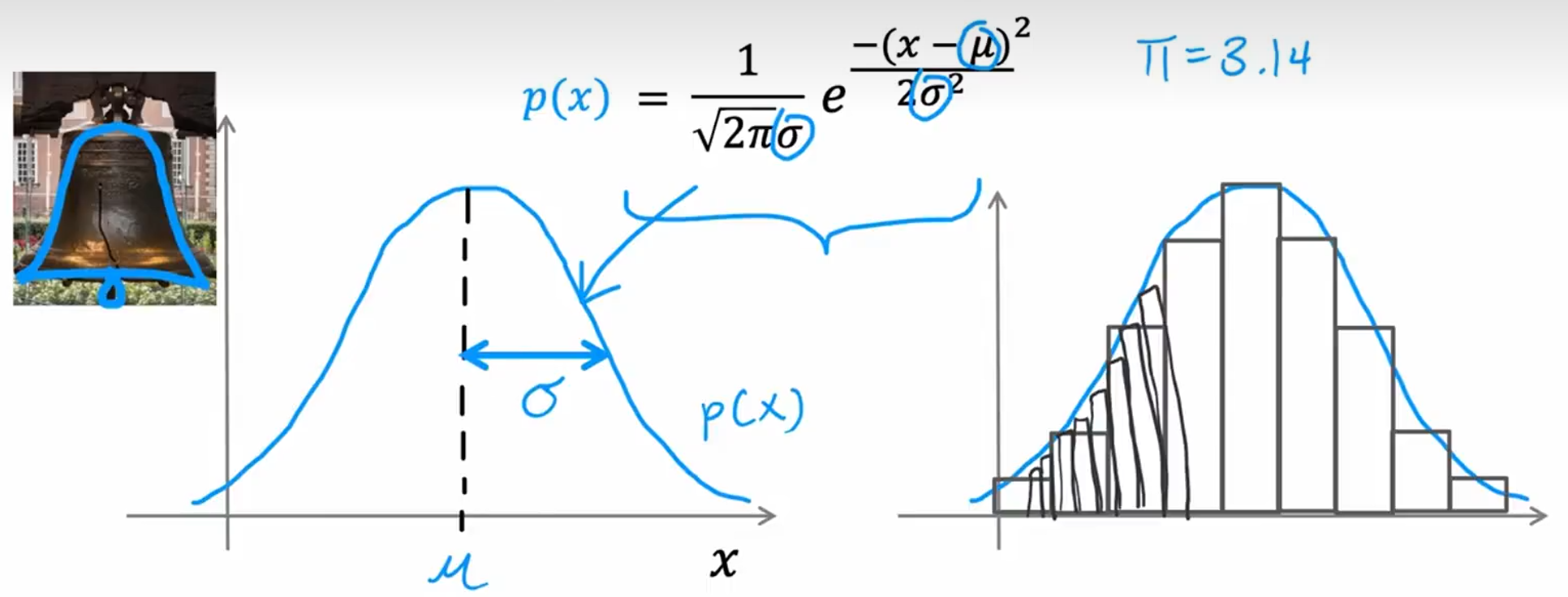
多个特征:
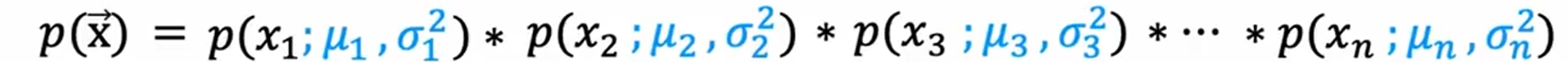
选择ε

如何选择特征
- 符合正态分布,不符合的进行变换,使更符合正态分布
异常检测vs监督学习
- 异常检测:
- 少量正样本、大量负样本
- 未来的异常和样本的异常不像
- 欺诈检测
- 监督学习:
- 大量正样本、大量负样本
- 未来的异常和训练集的异常相似
- 垃圾邮件
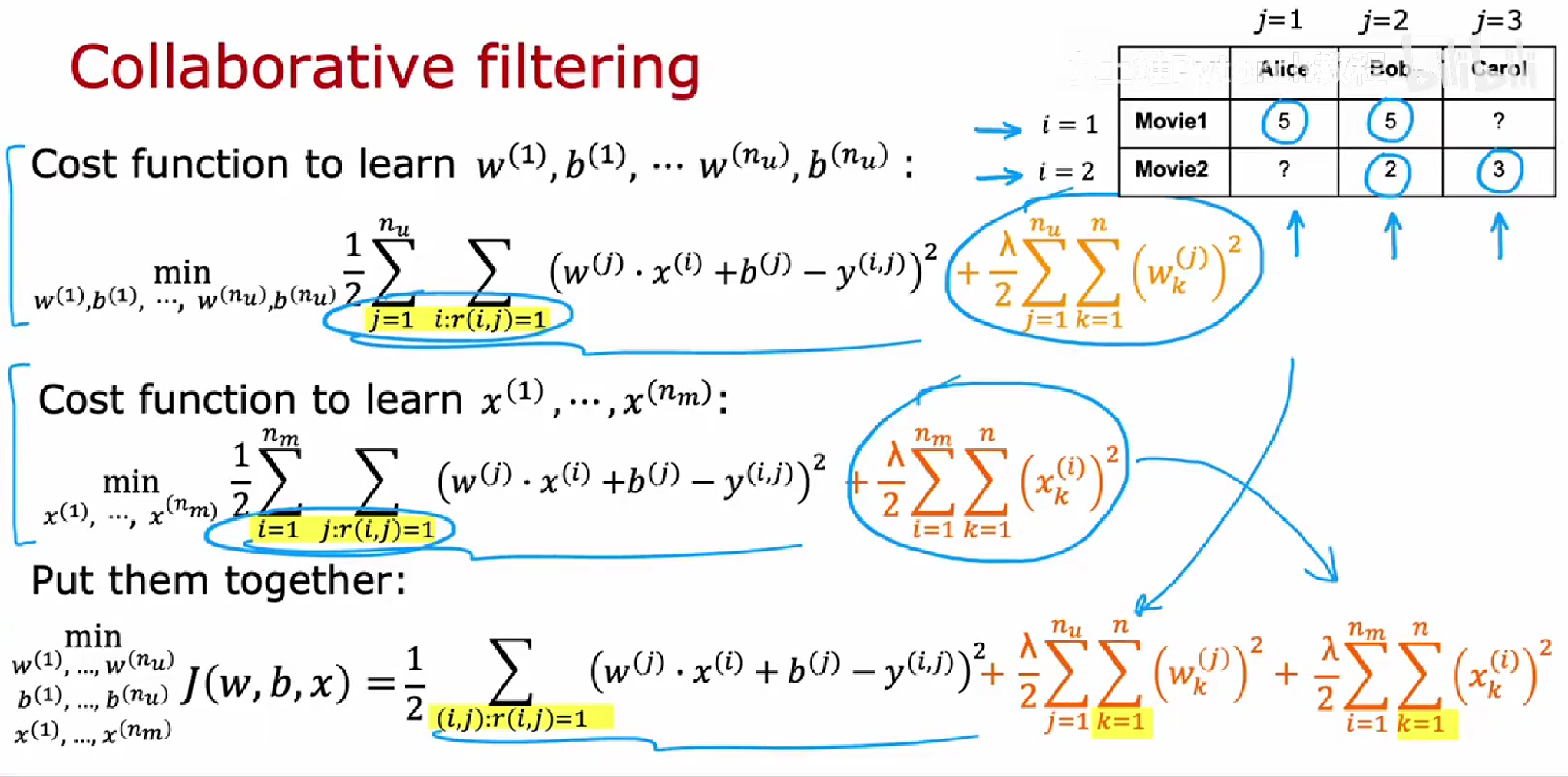
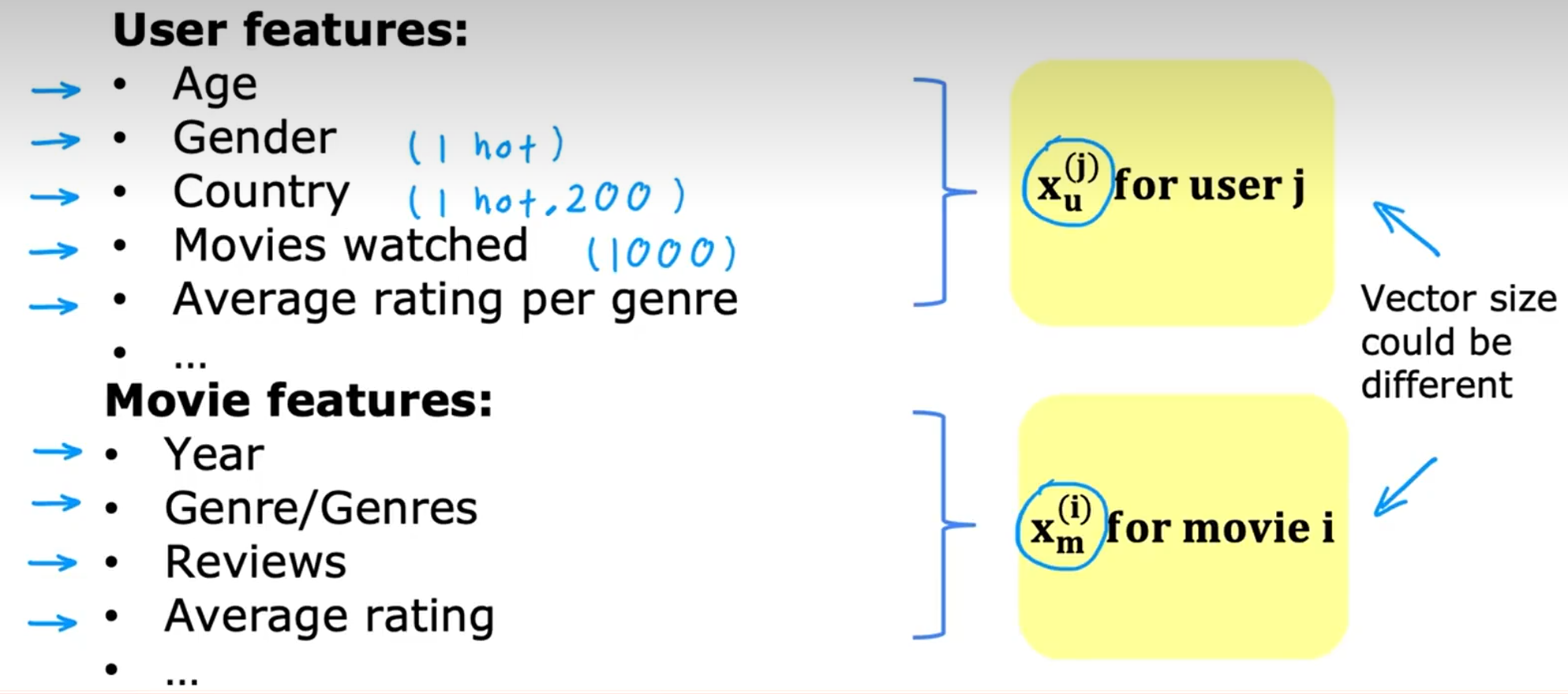
推荐系统
根据用户对电影的评分,向用户推荐电影
项目特征
均值归一化
对没有给电影评分的用户给出更合理的预测
每个数减去平均值
预测要加上均值μ
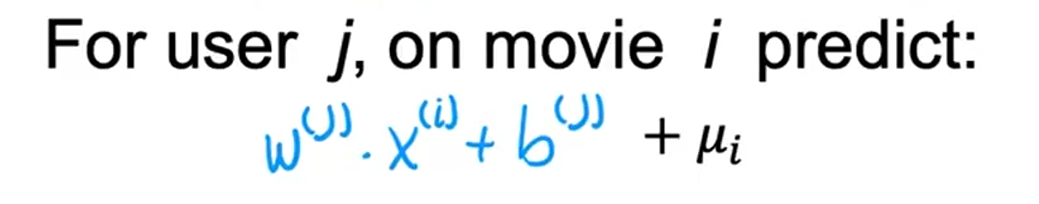
协同过滤(多个用户对多个项目进行评分)
学习电影特征x和用户参数w, b
预测电影的特征和用户对电影的评分
可以推广到二元标签
缺点
- 不擅长处理冷启动
- 冷启动:一个新item,few users评分过,系统怎么对item进行评分
基于内容过滤
根据用户和item本身的特征来推荐
构建本身的特征向量
预测:

- 如何转换?用nn
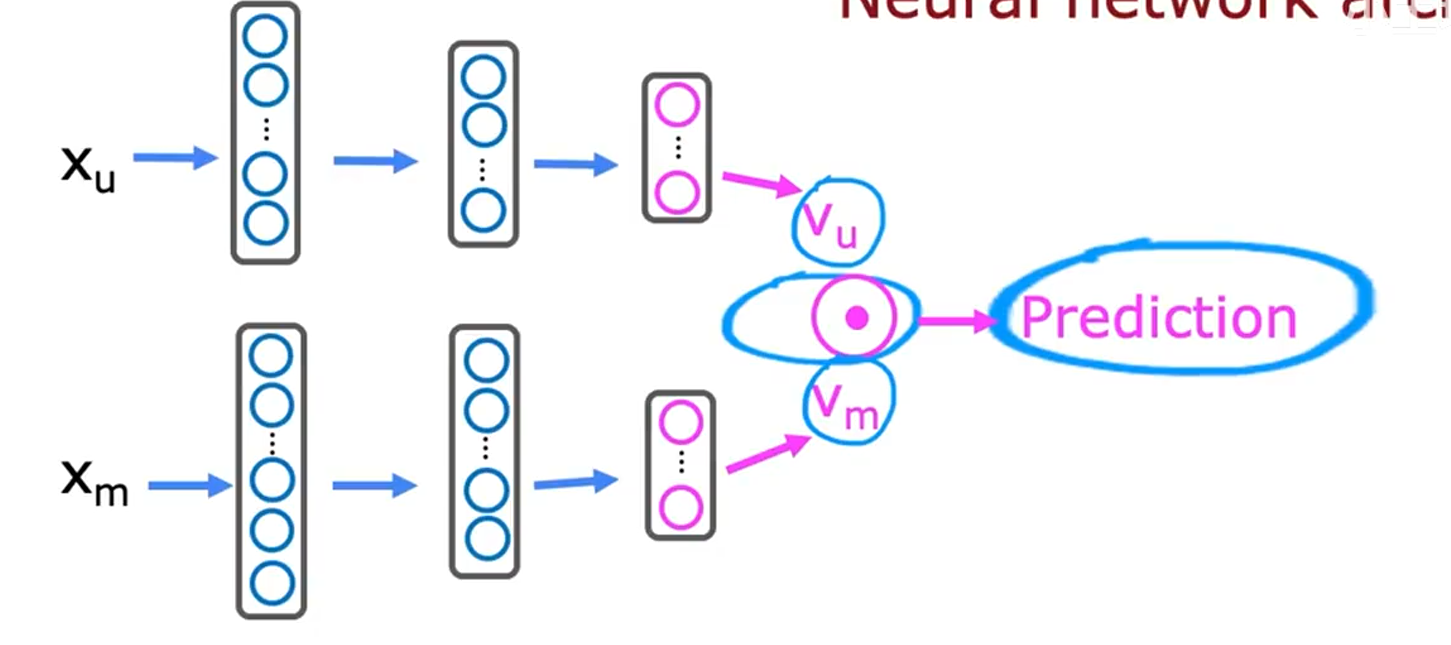
loss:

发现相关item
根据一个item,给出相似item:找到特征x最相似的item
判断相似:
找到最小
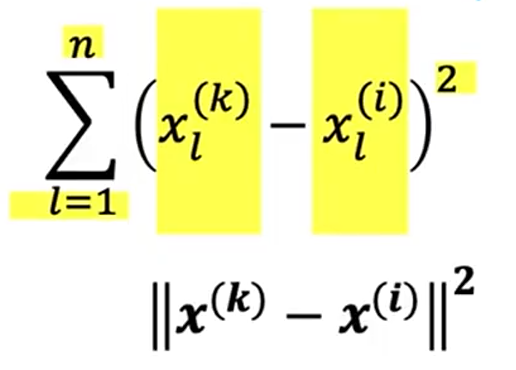
从大型目录中推荐
- 检索:检索出合理的推荐项目(根据最近10部、看的最多的类型。。。)
- 排序:
PCA(主成分分析算法)
将大量特征进行减少进行数据可视化
找到一个或多个新轴
将轴进行旋转,看点在新轴上的投影,尽可能保持原始的方差
强化学习
为什么不用监督学习?
因为很难获取这样一个state和action对应起来的数据集
需要一个奖励函数,判断什么时候做的好
核心要素:状态、动作、奖励、下一个状态
回报
系统获得奖励的总和

决策
强化学习的目标是找到决策函数,告诉我们如何在每个状态下采取行动以最大化回报
Q(s, a)状态-动作值函数
在s状态采取a动作后并在此之后最优表现所获得的回报
bellman贝尔曼方程
用于计算QSA=即时奖励+未来奖励
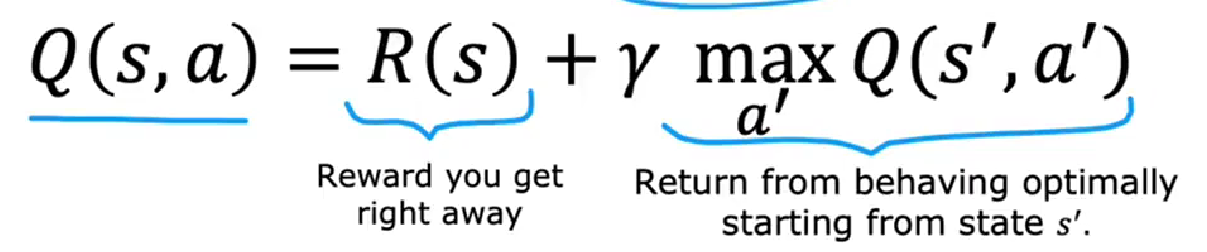
通过nn学习QSA
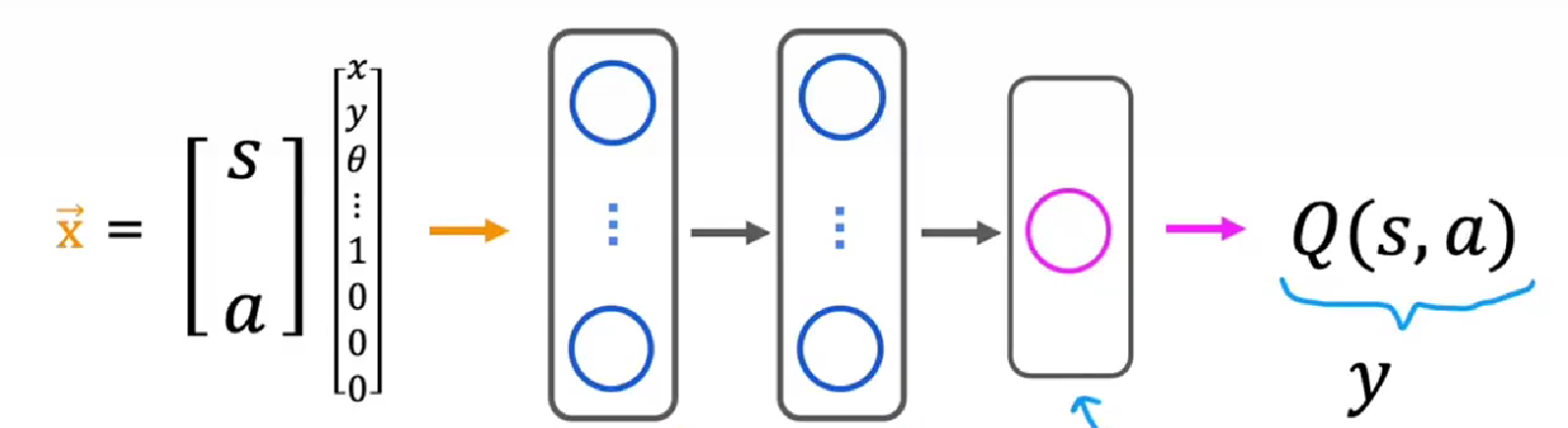
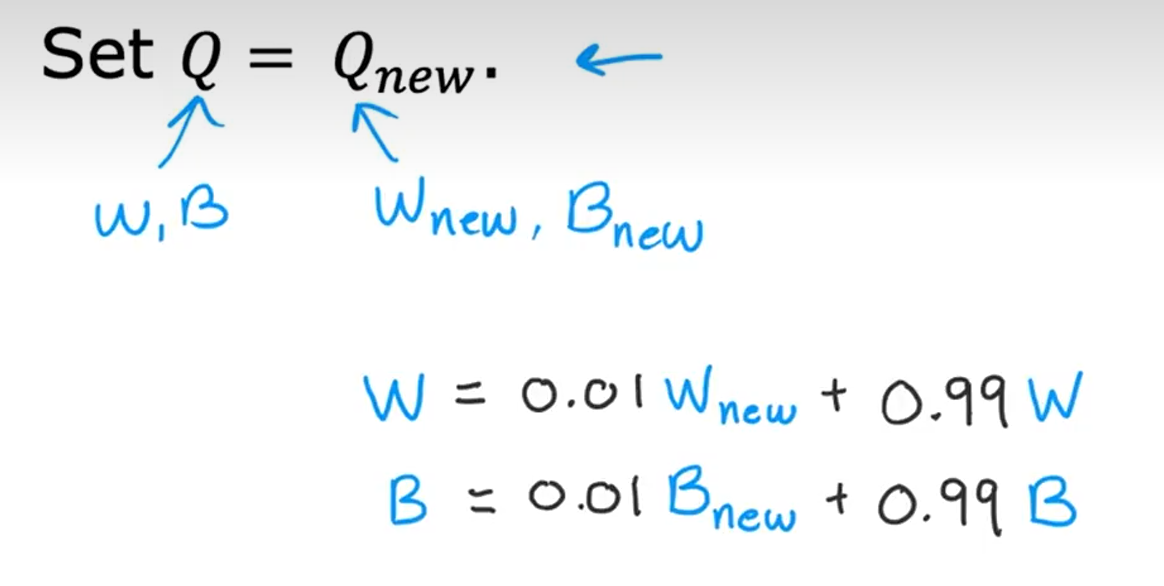
改进
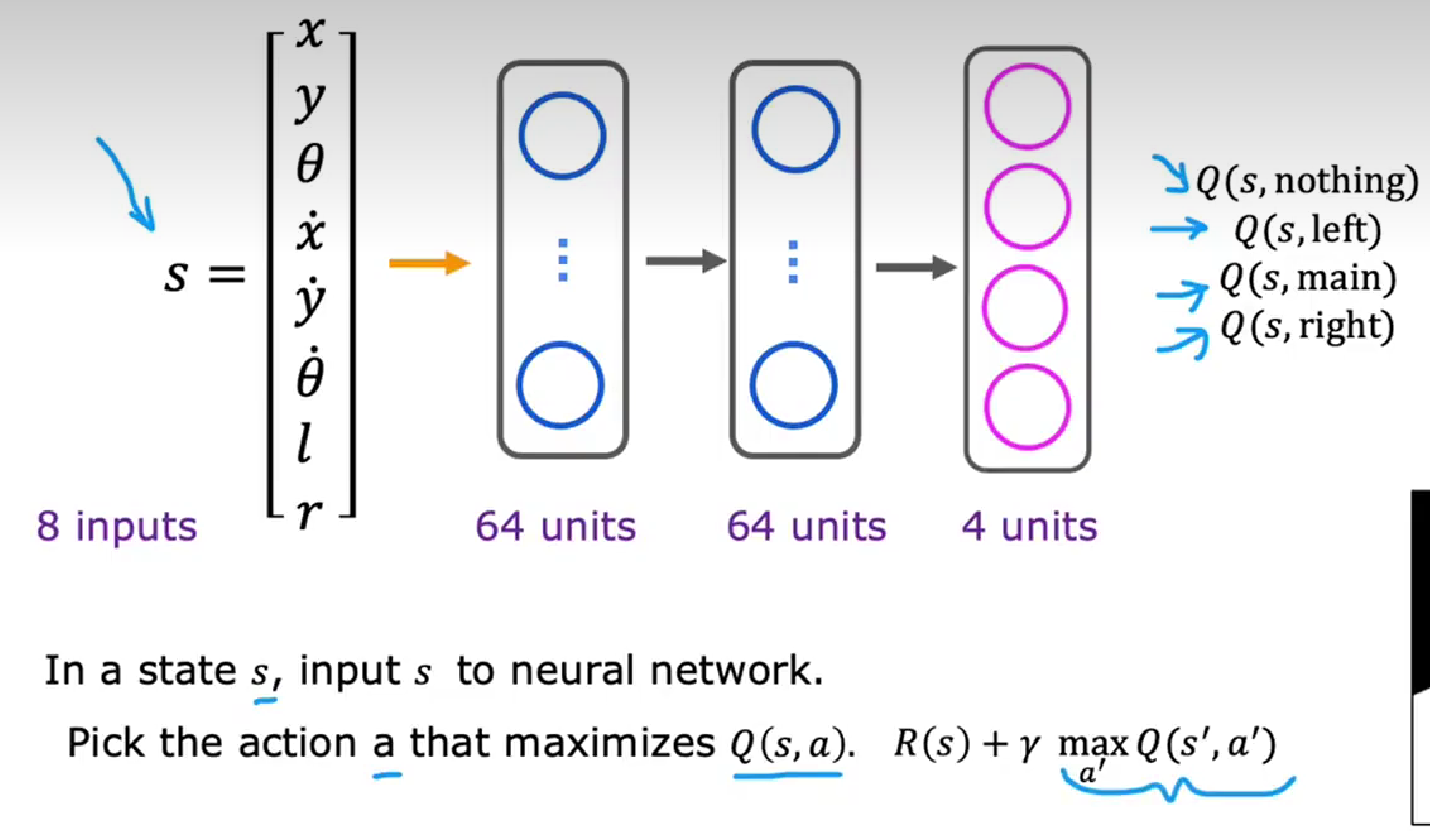
小批量minibatch
软更新