DL

DL
WisdomX神经网络
- 结构:input -> 神经元激活函数 -> output
- 层数:隐藏层、输出层,不包括输入层
- 激活函数:
- sigmoid=1/(1+e^(-x)) (适用于二元分类)
- ReLU=max(0, y)
- leaky ReLU=max(0.01y, y)
- tanh
- 损失函数Loss(w, b):要找到损失函数的最小值
- 优化函数
- 梯度下降:用来找到损失函数最小时的w和b
- 参数=参数-学习率*loss对参数的导数
- 梯度下降:用来找到损失函数最小时的w和b
逻辑回归
loss:
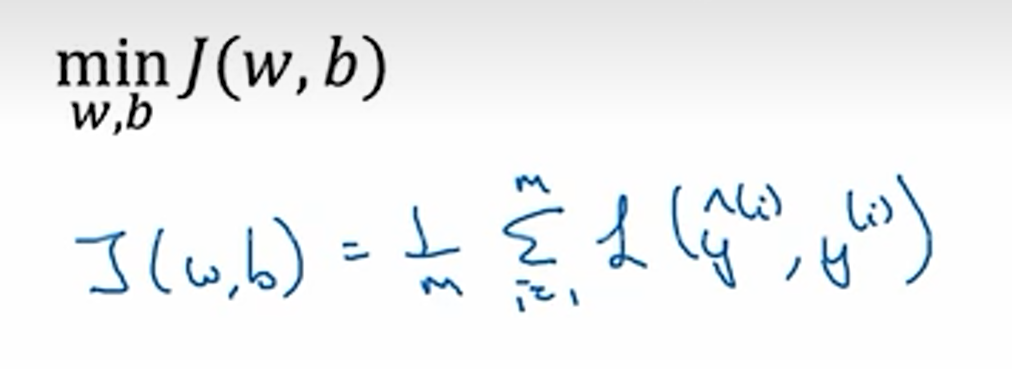
计算图
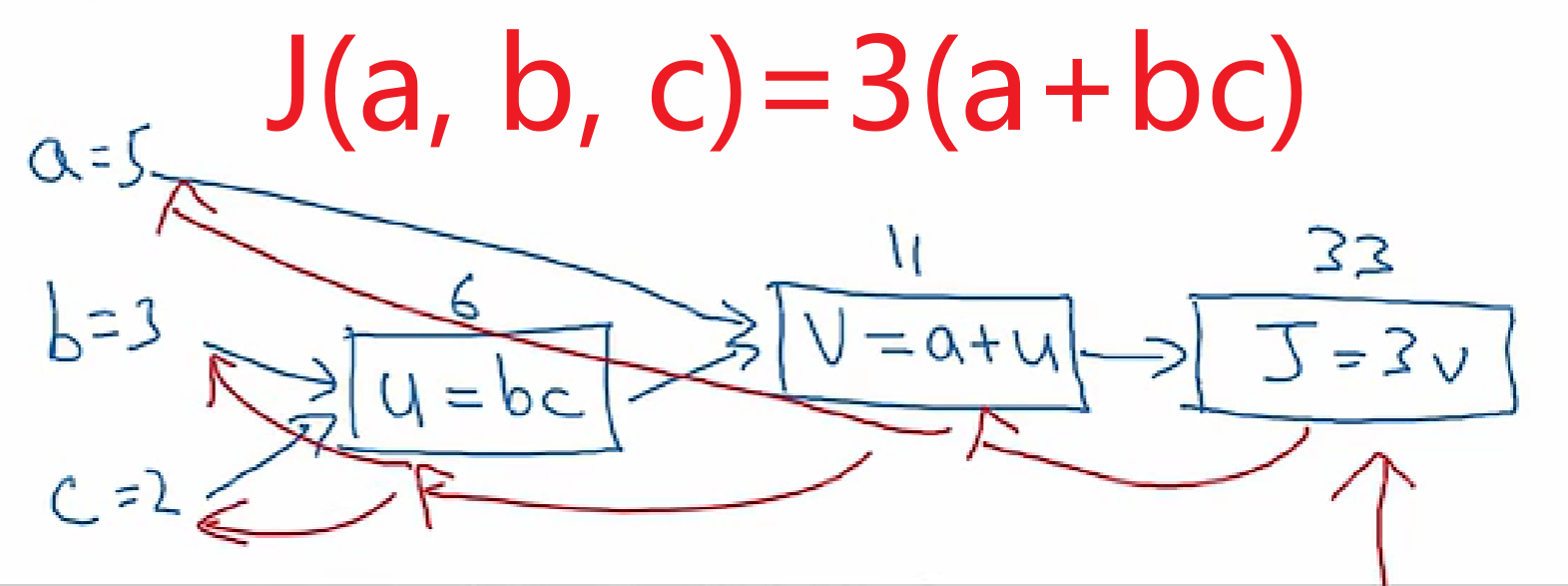
- 计算loss:前向传播
- 计算梯度:反向传播
向量化
减少for循环,提高代码效率
1 | import numpy as np |
Py中的广播
1 | cal=A.sum(axis=0) # axis=0垂直求和,axis=1水平求和 |
- 编写建议
1 | a=np.random.randn(5,1) # use this - two argument |
激活函数
要用非线性激活函数,不用的话,就相当于计算一个线性激活函数,还不如去掉所有隐藏层
非线性激活函数是神经网络的关键
权重初始化
随机初始化
1 | np.random.randn((2,2)) # 随机初始化为一个二维矩阵 |
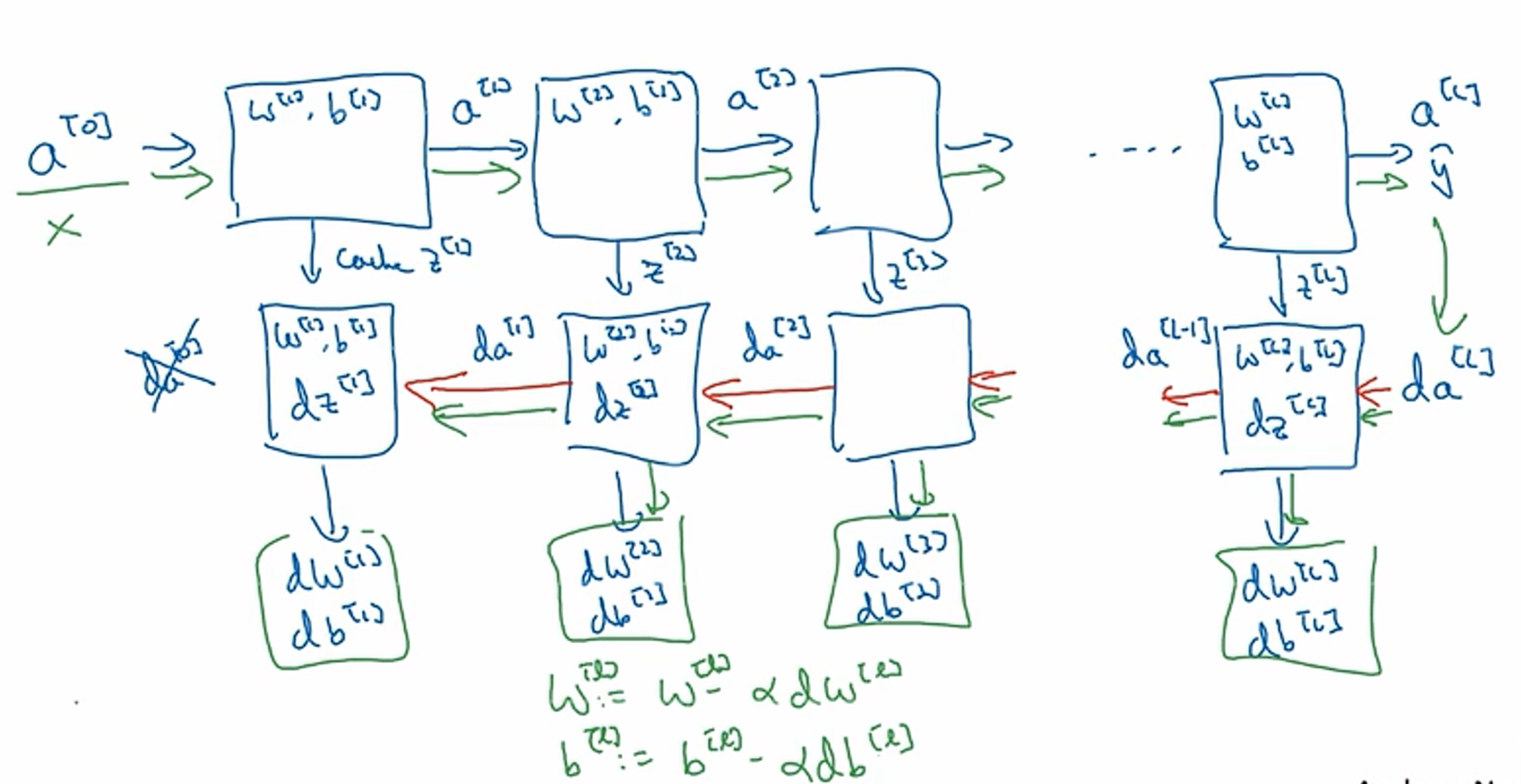
前向传播
- 结构
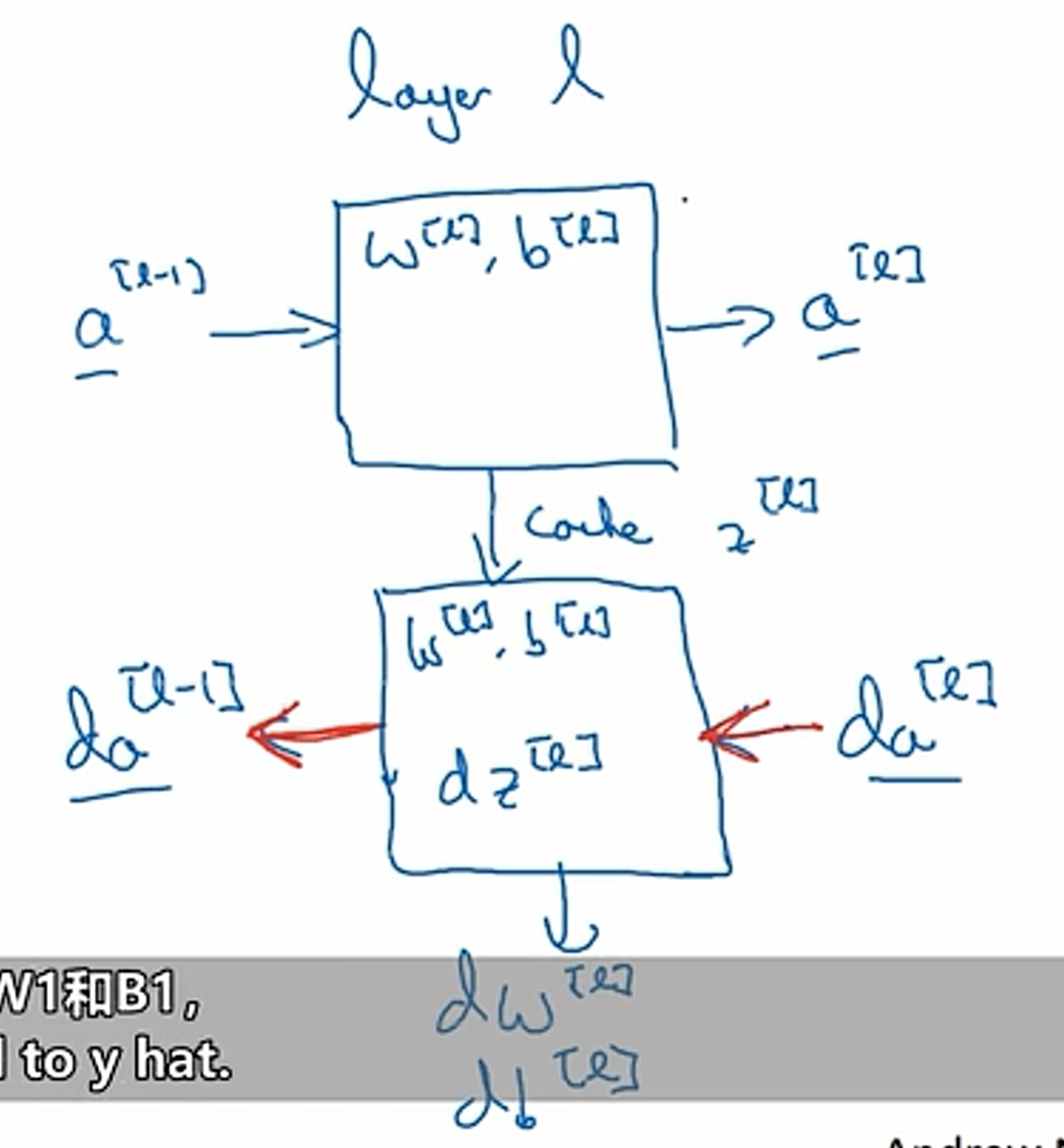

反向传播

前向和反向传播
矩阵维数
单个样本

m个样本
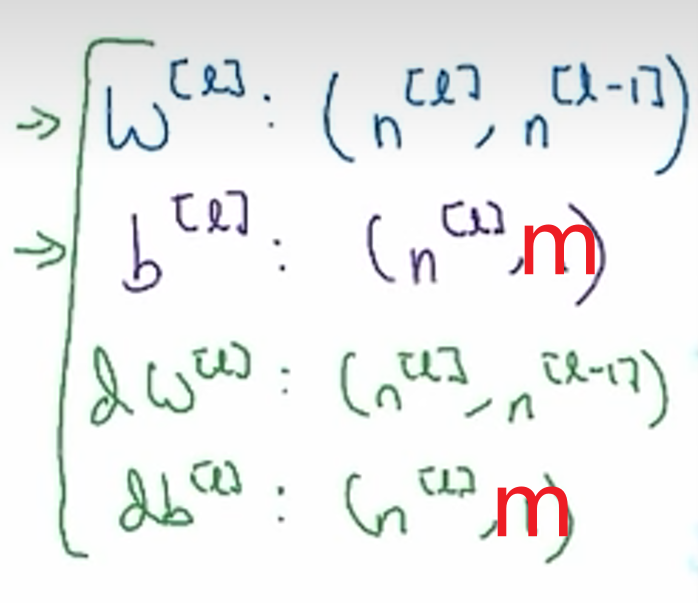
参数
w,b
超参数
学习率,迭代次数,隐藏层层数,隐藏神经元个数,激活函数,λ
数据集
训练集、开发集/交叉验证集:测试哪个算法更好、测试集:对算法给出评估
偏差bias、方差variance
偏差bias:用于训练集的表现
- 尝试更大的网络结构
- train longer
- 找到适合的nn结构
方差variance:用于测试集的表现
- more data
- 正则化
- nn结构
正则化
解决过拟合
逻辑回归中
l2正则化:λ为正则化参数
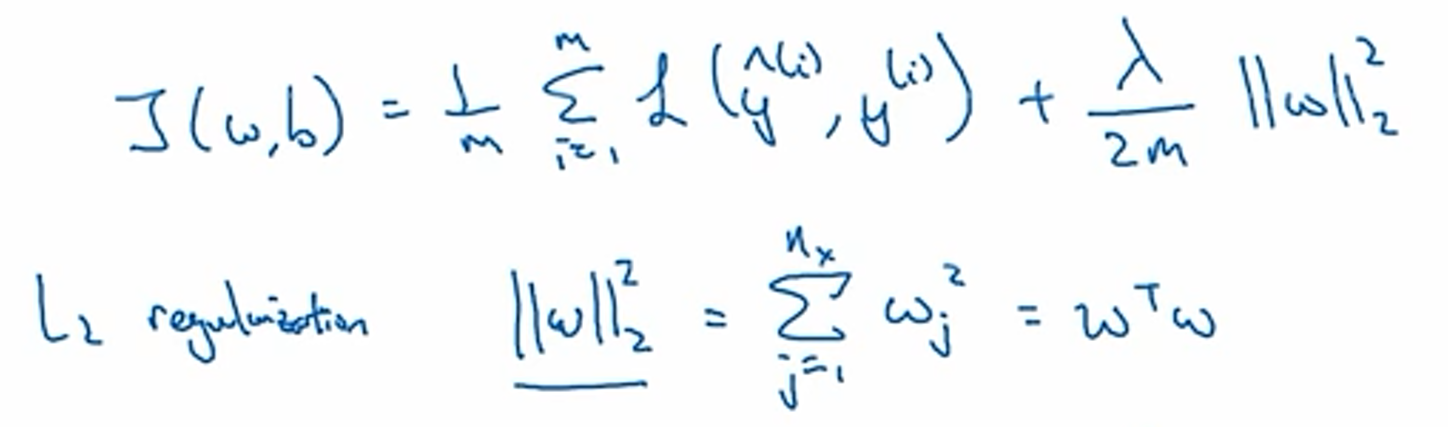
python中
记为lambd
神经网络中
L2正则化
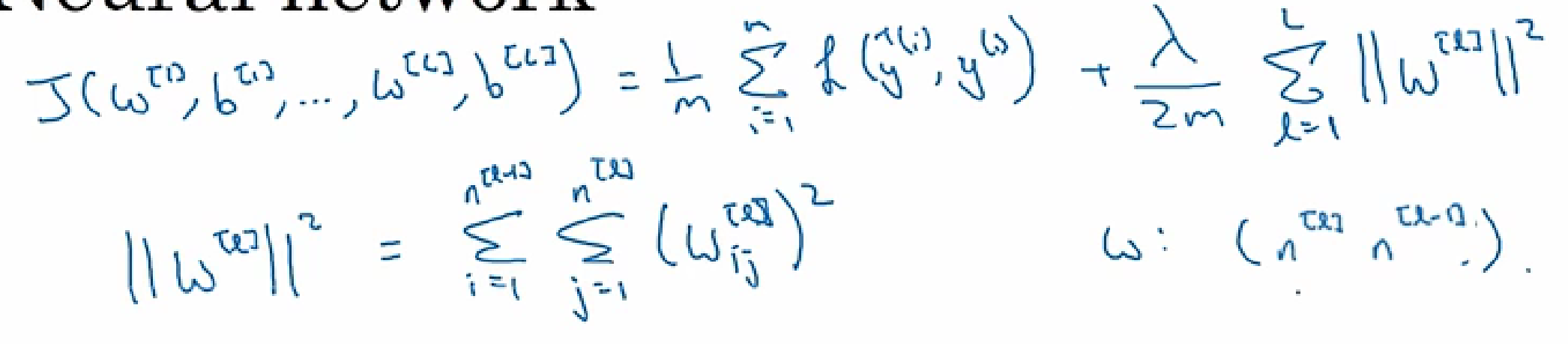
正则化后的反向传播
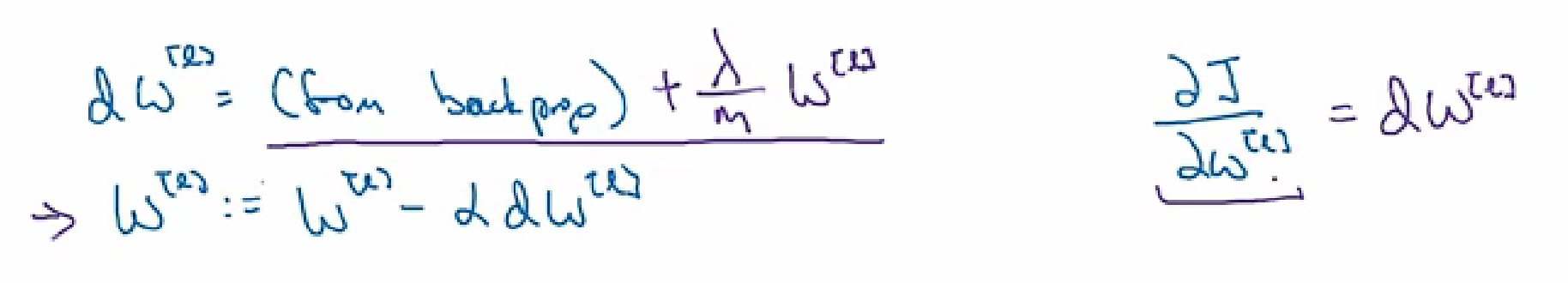
dropout
解决过拟合
对每一层的每一个结点进行概率判断是否抛弃
数据扩增
早终止法
归一化
输入特征的尺度不同时用
减去均值、除以均方差
训练集和测试集用一样的方式
梯度爆炸、消失
w过大或过小导致y_hat过大或过小
- 解决方案
- 细致地随机初始化
初始化:
relu:2/n
tanh:(1/n)^(1/2)
优化函数
梯度下降
指数加权平均
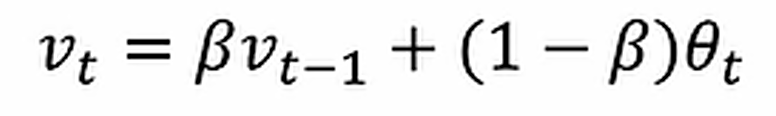
v0=0
v1=βv0+(1-β)θ1
v2=βv1+(1-β)θ2
…
- 偏差修正
在初期,估计值会比较低
所以vt要除以1-β^t
动量梯度下降
计算梯度的指数加权平均,加速梯度下降
β一般为0.9
不需要偏差修正
RMSprop均方根传递
加速梯度下降
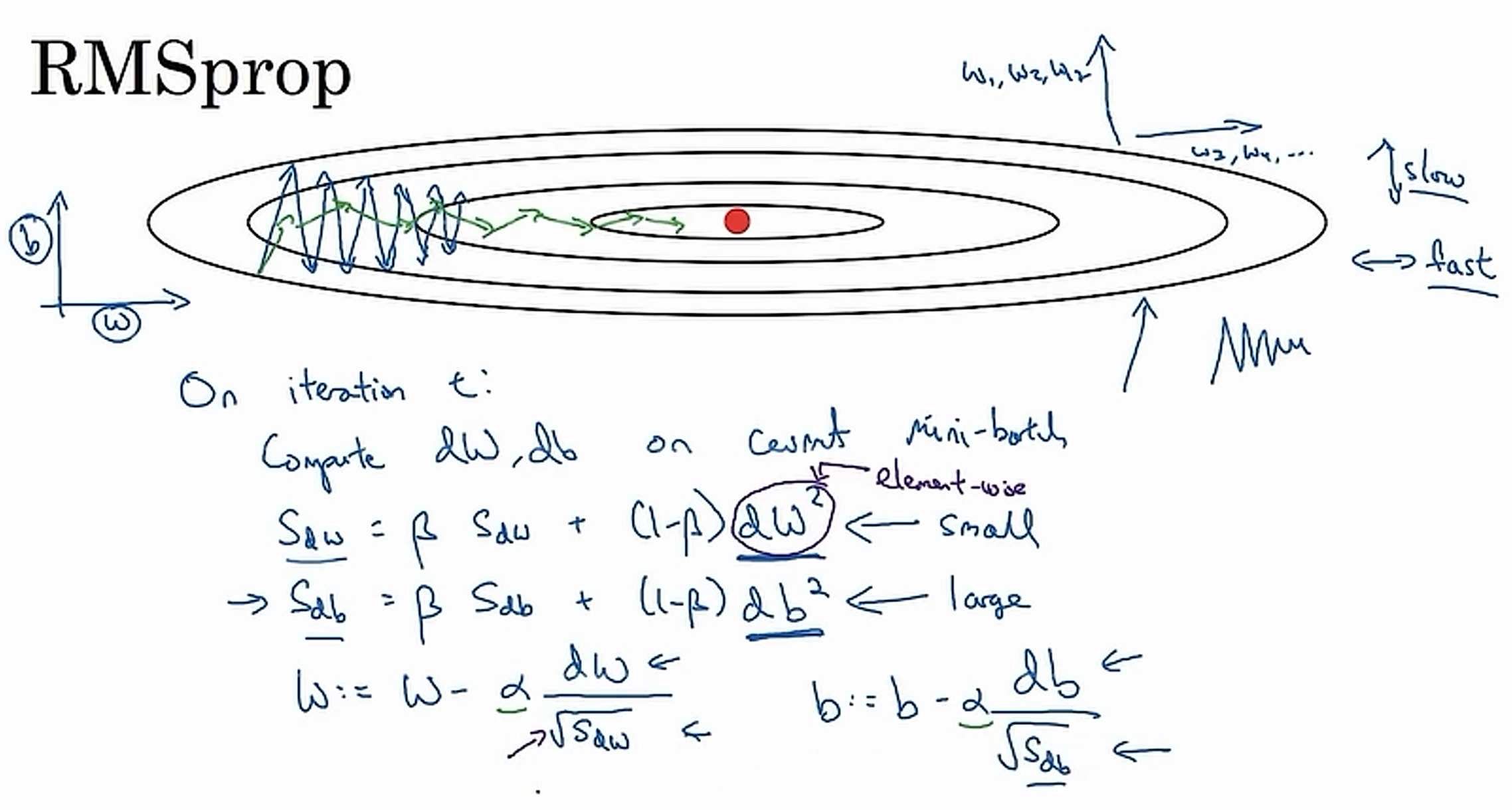
Adam

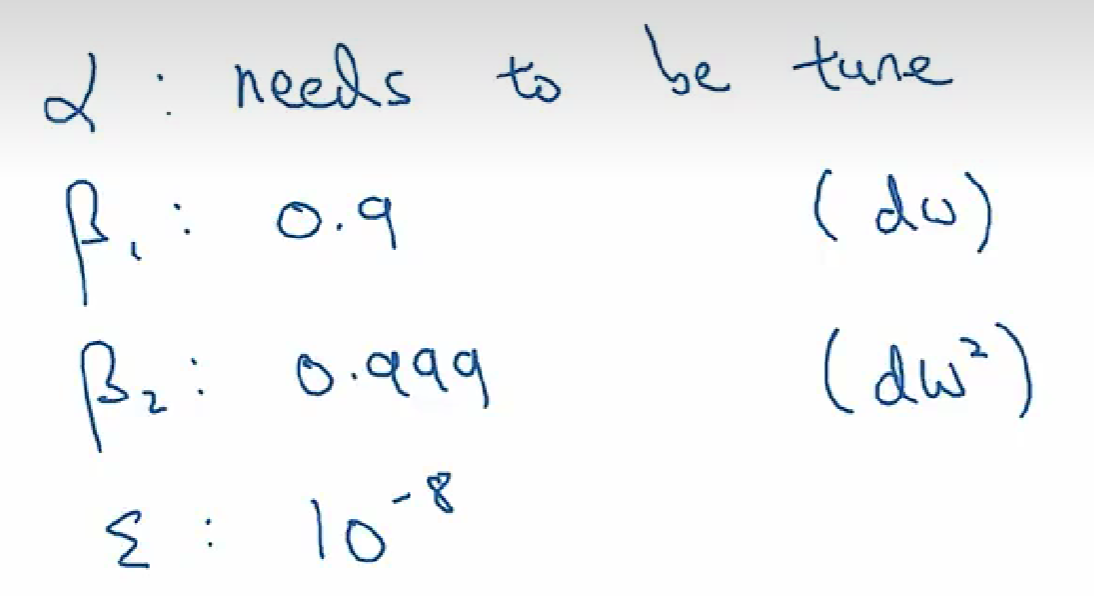
损失函数
0-1损失函数
0 if y = y_hat
1 if y != y_hat
平方损失函数
(y-y_hat)^2
学习率衰减
α=α0/(1+衰减率*epoch_num)
局部最优
高维空间中,更多的是鞍点,而不是局部最优点
batch norm批量归一化
不仅在输入层,也在隐藏层
softmax
正交化
- train set(bias问题)
- 更大的网络
- Adam
- dev set(variance问题)
- 正则化
- bigger train set
- test set
- bigger dev set
- real world
- dev set
- cost function
评价指标
精确率、召回率、F1分数(结合精确率、召回率)
多标签学习
不是softmax
端到端
直接判断x和y的关系,但这需要大量数据
计算机视觉
图像分类、目标检测、神经风格转换
边缘检测
通过卷积过滤器可以得到边缘
卷积
n*n图片和f*f过滤器=(n-f+1)*(n-f+1),f一般用奇数
Valid卷积和Same卷积
步长

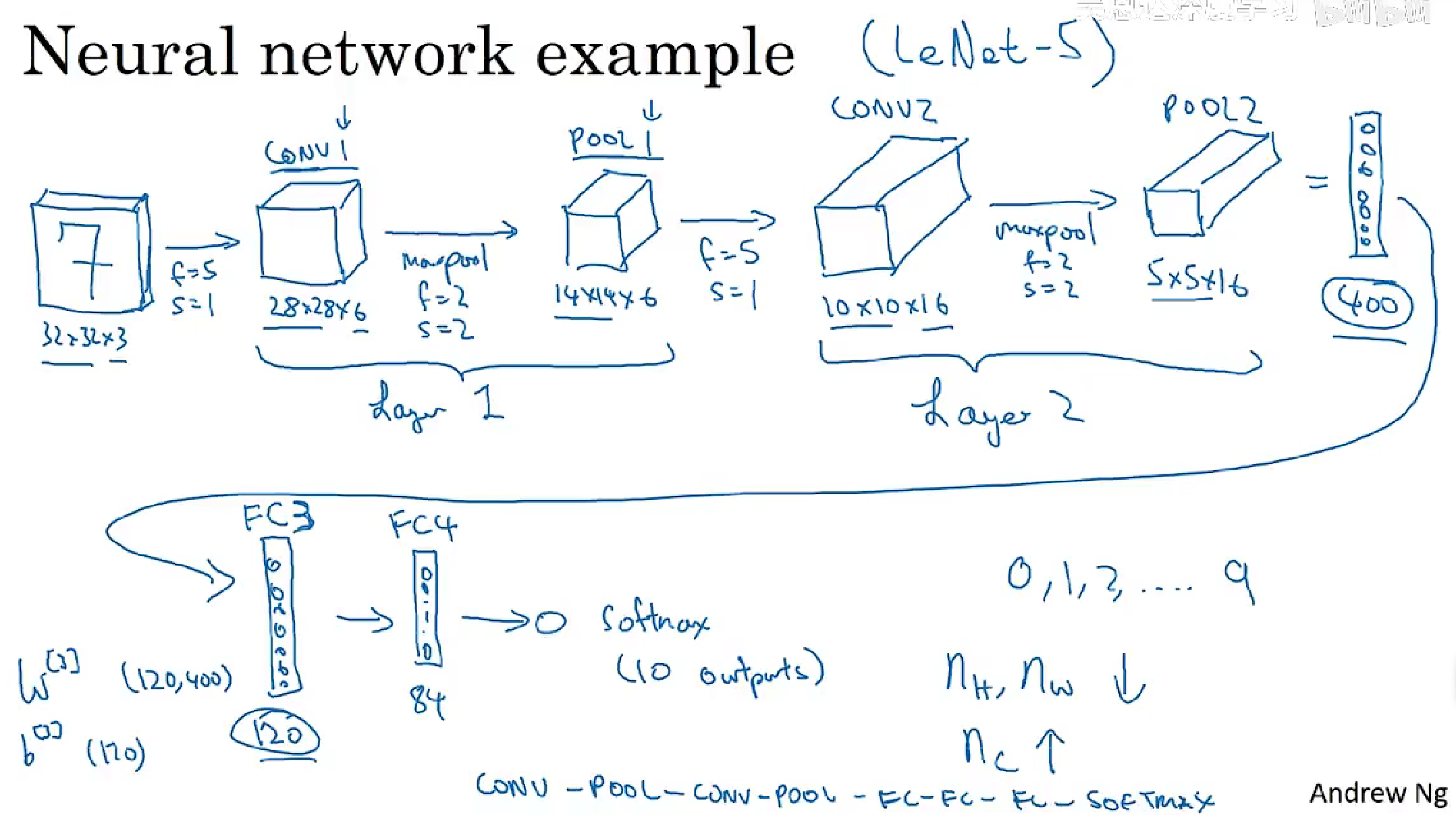
CNN卷积nn

卷积层conv
池化层pooling
max pooling:如果在filter中检测到了特征,就保留最大的数值
average pooling:
- 全连接层
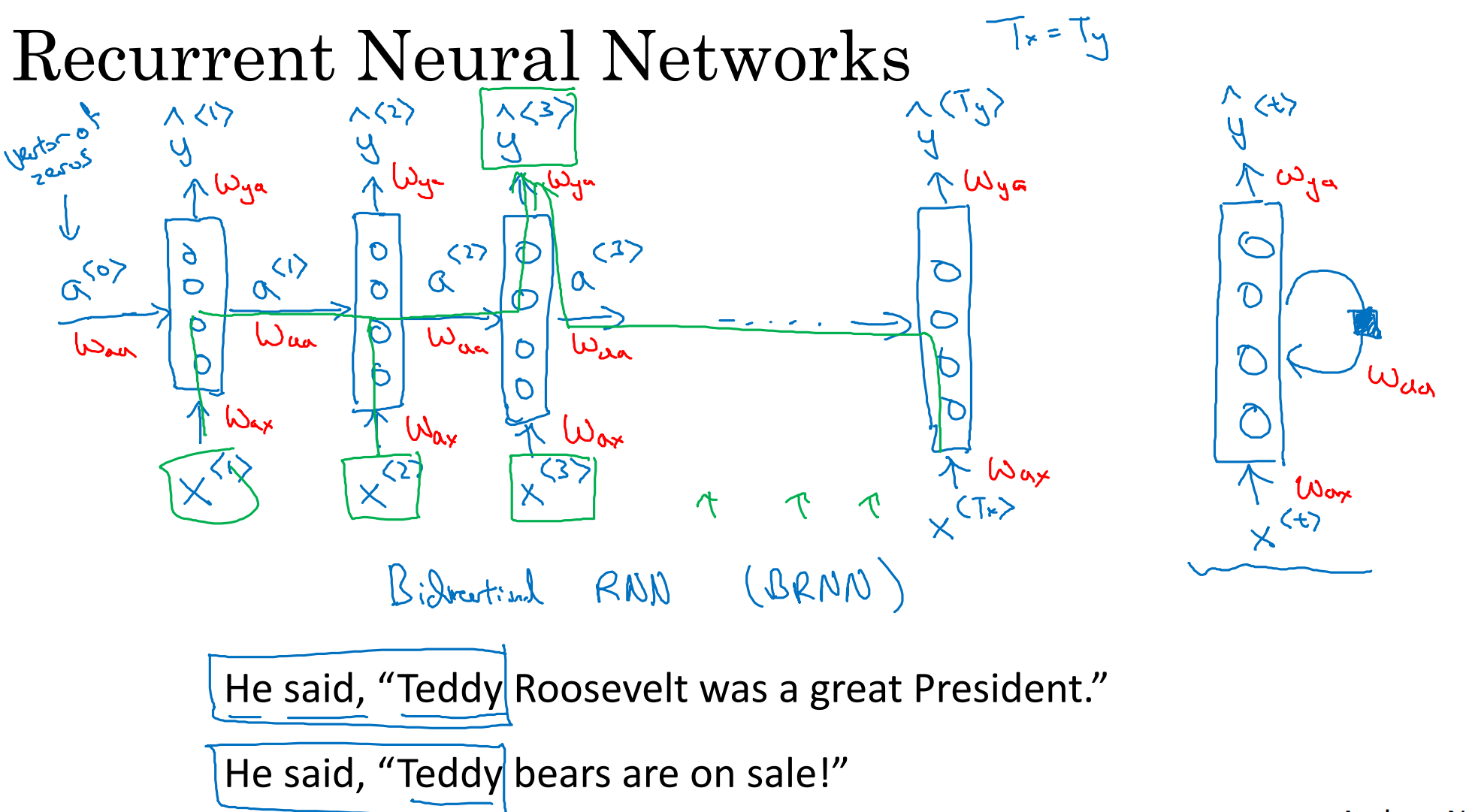
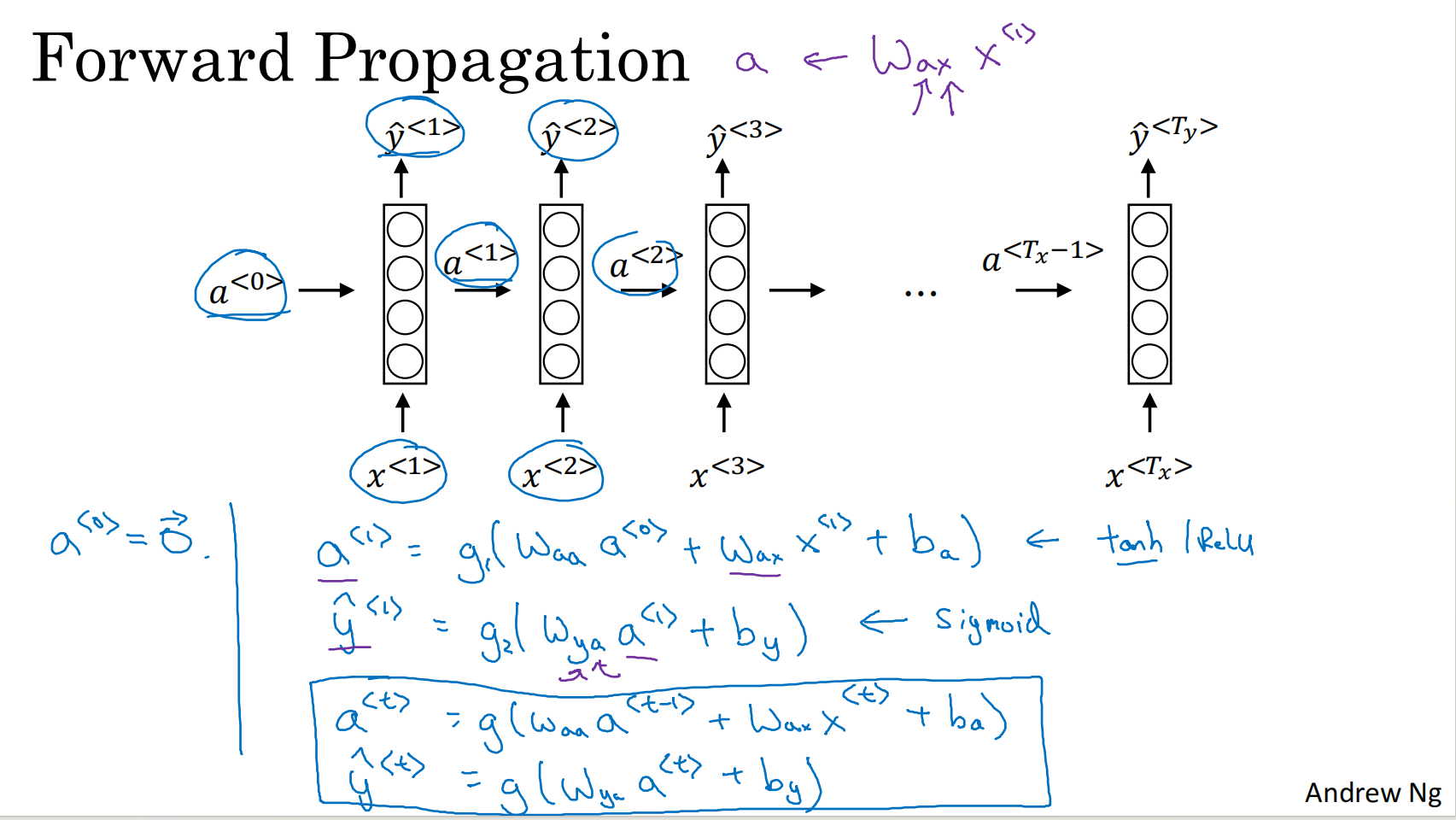
RNN
存在梯度消失问题,只能用前面的信息进行预测,很难捕捉远距离依赖
GRU
用门控制信息的流动
LSTM
用门控制信息的流动
BiRNN
深度RNN
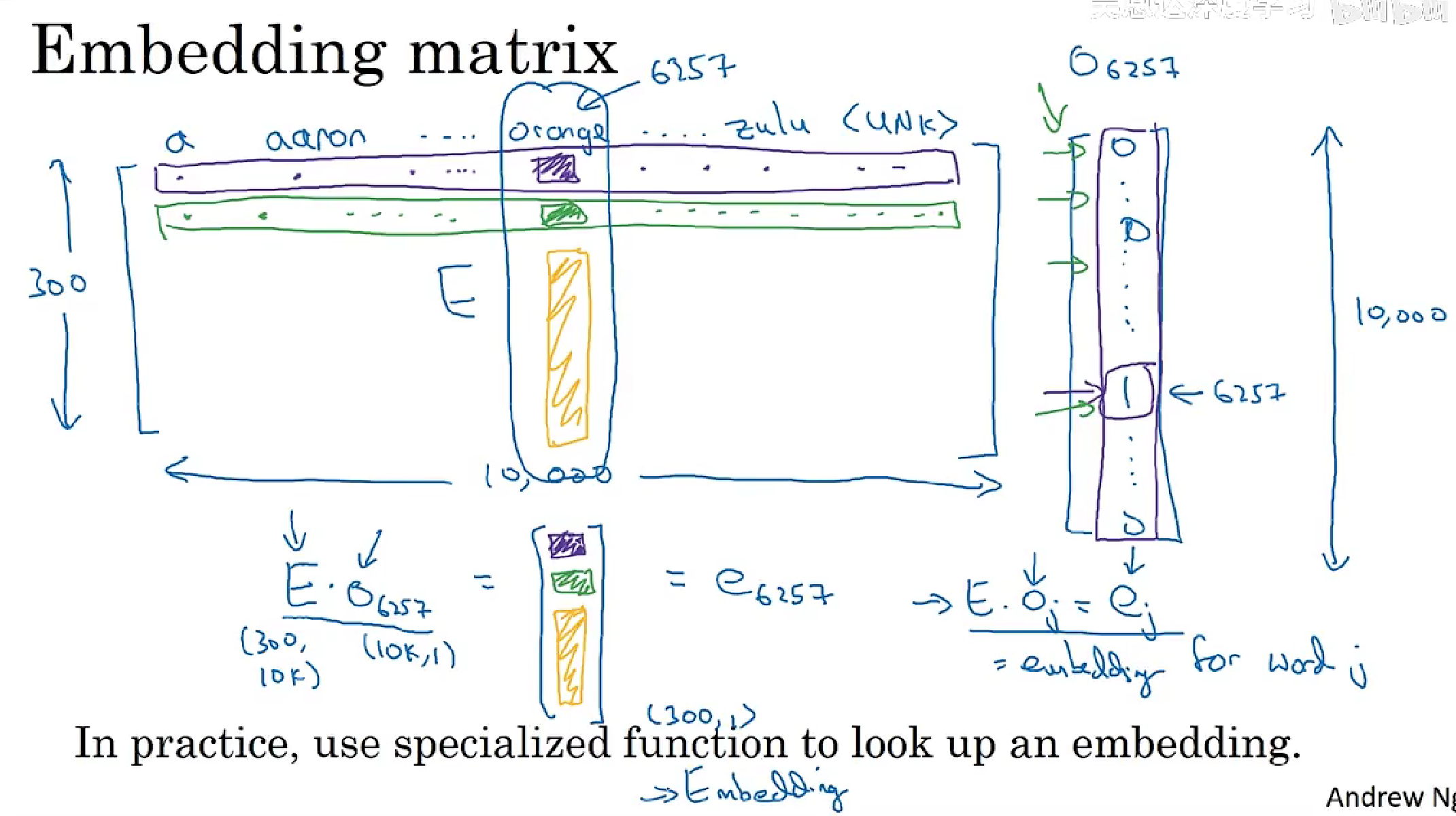
词嵌入
词之间的关系、将词嵌入到高维空间中的一个点上
词嵌入学习算法得到的是嵌入矩阵E
两个向量之间的相似度函数
用于类比推理
- 余弦相似度
- 欧几里得距离
词嵌入矩阵
学习词嵌入得到词嵌入矩阵
Word2Vec
Skip-Gram
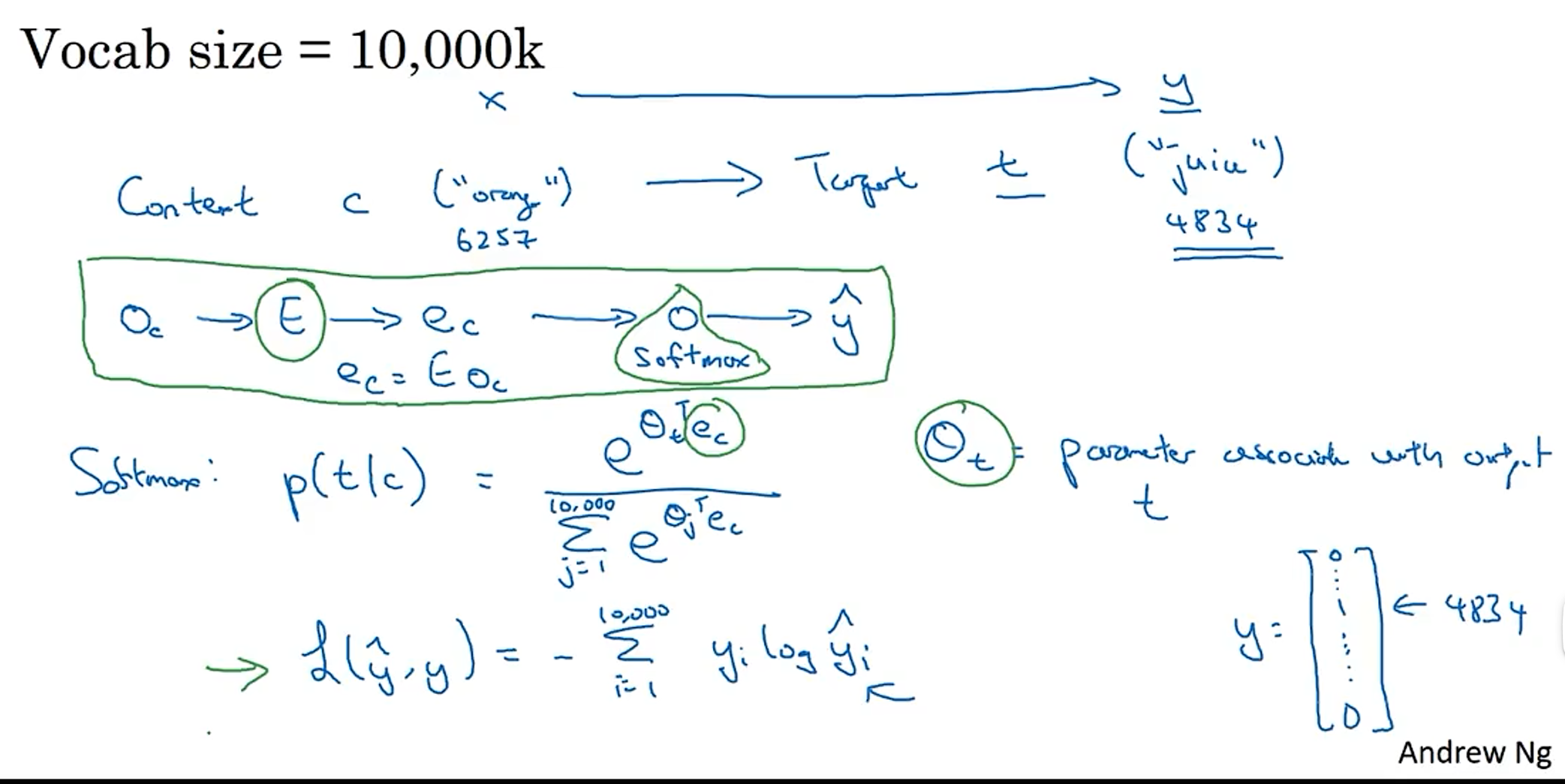
负采样法
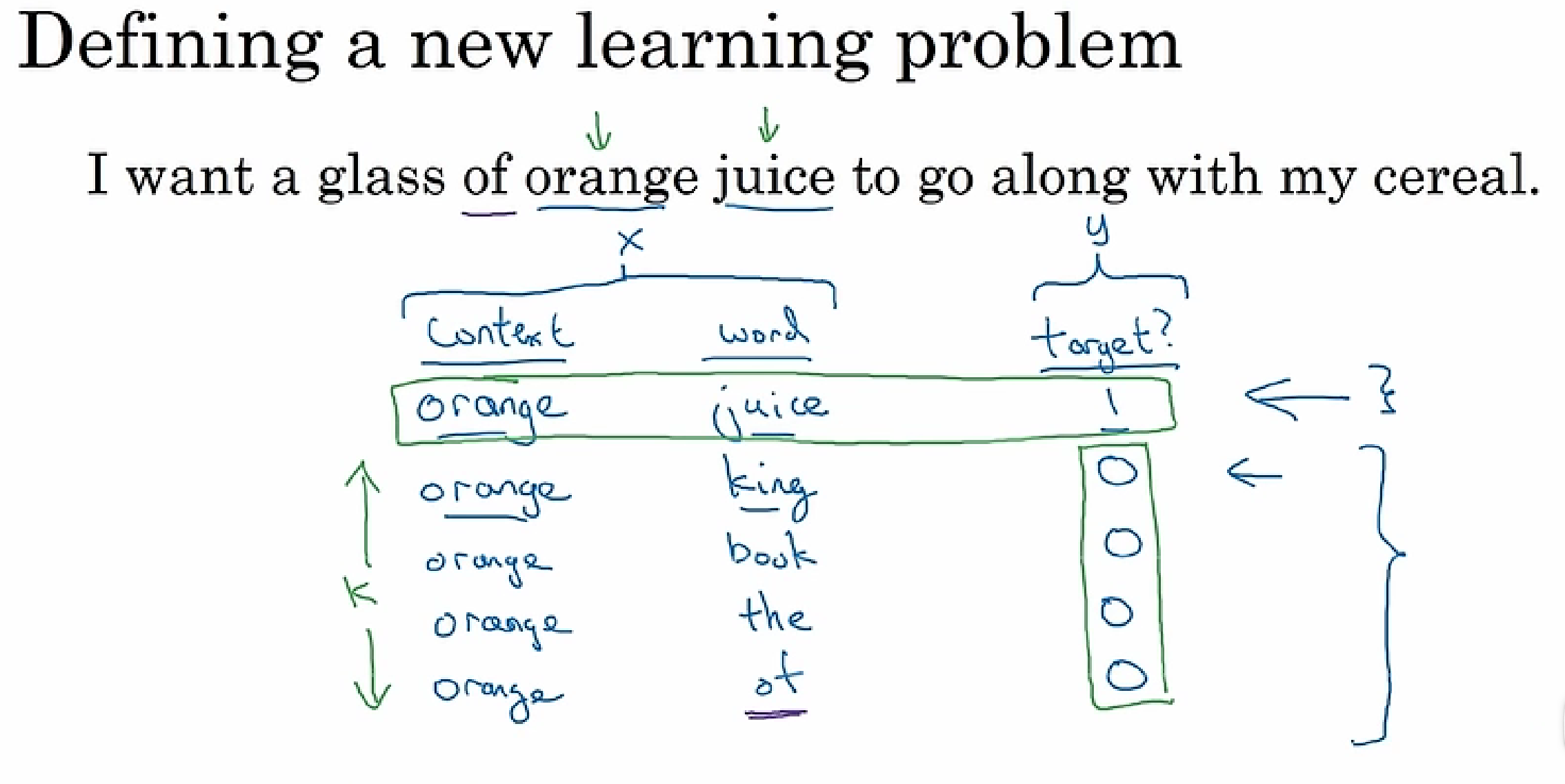

GloVe
xij:
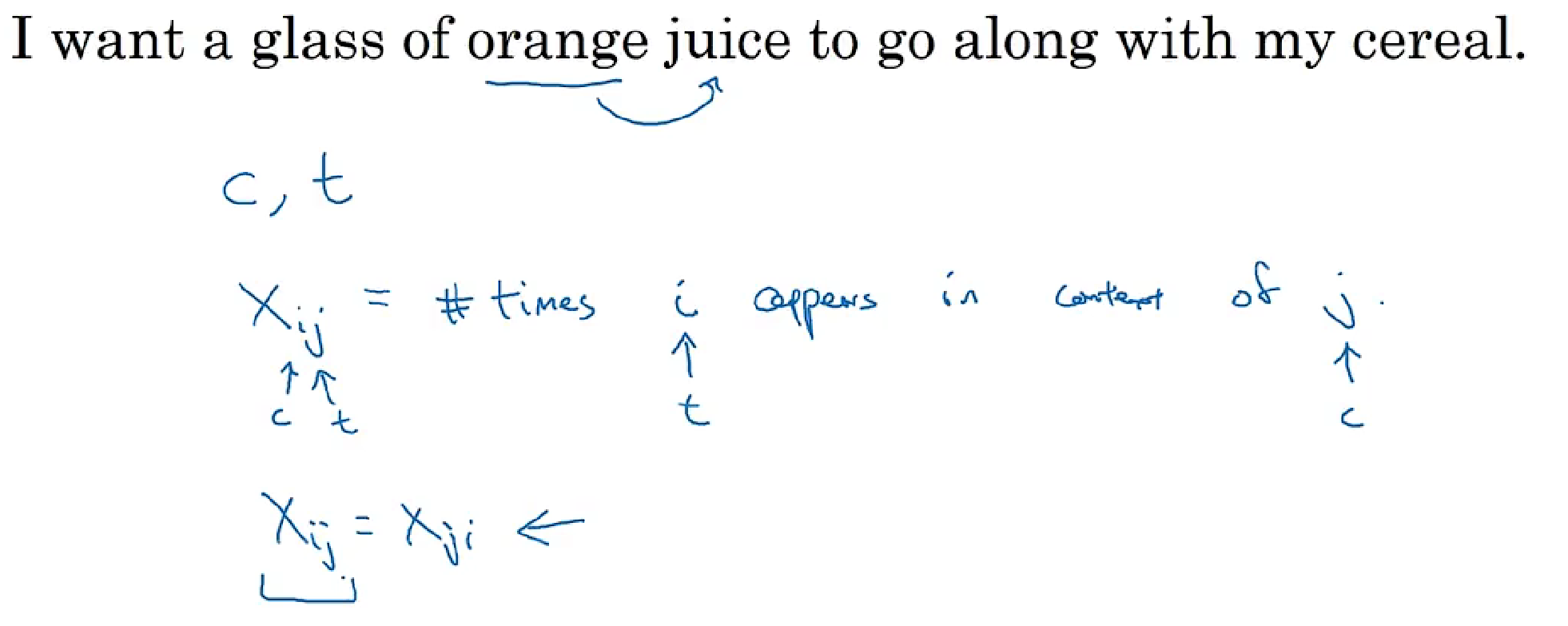
目标函数,f(xij)是权重
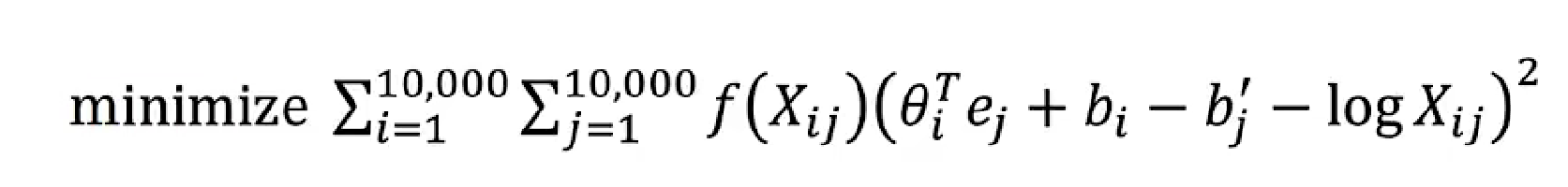
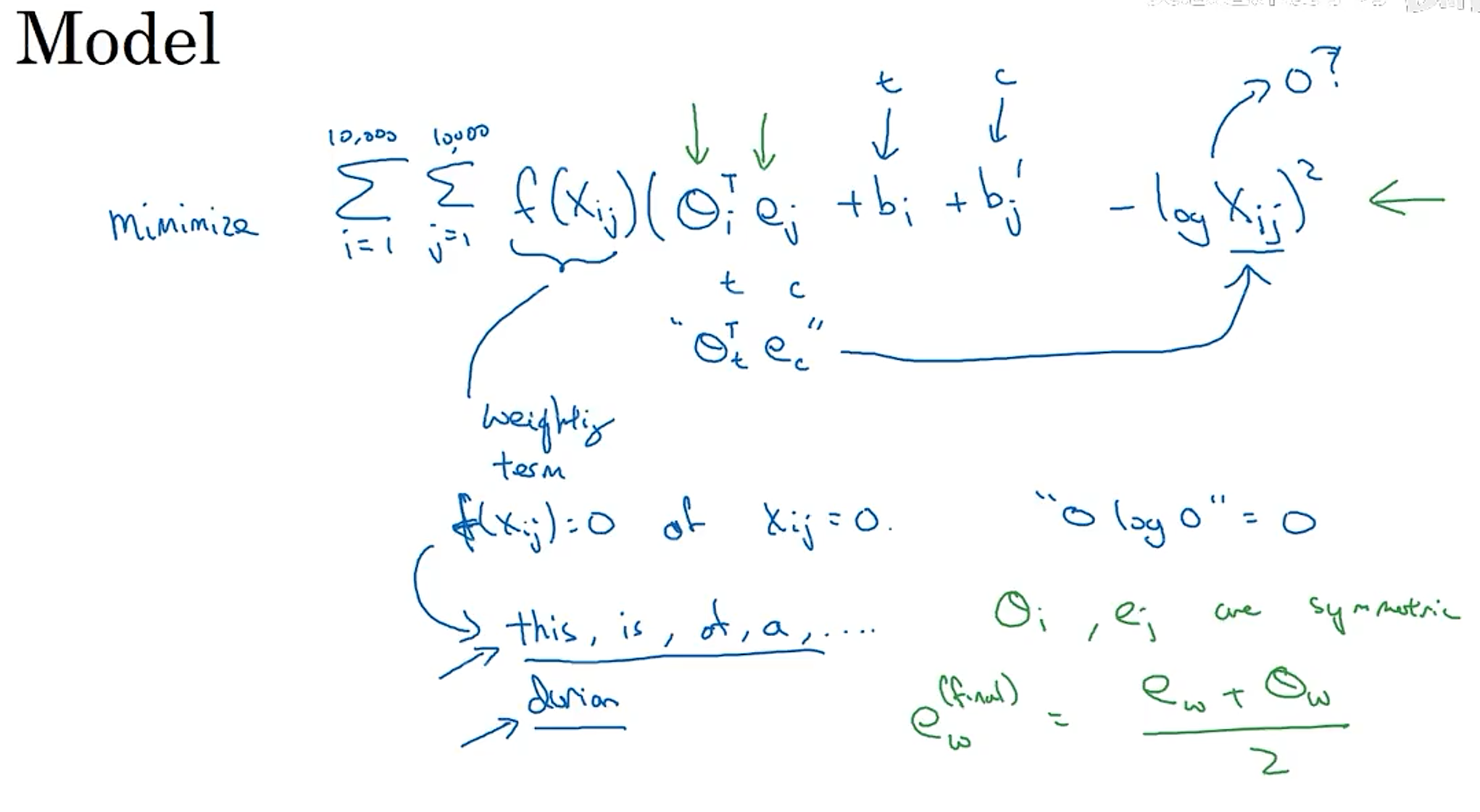
消除偏见
例子

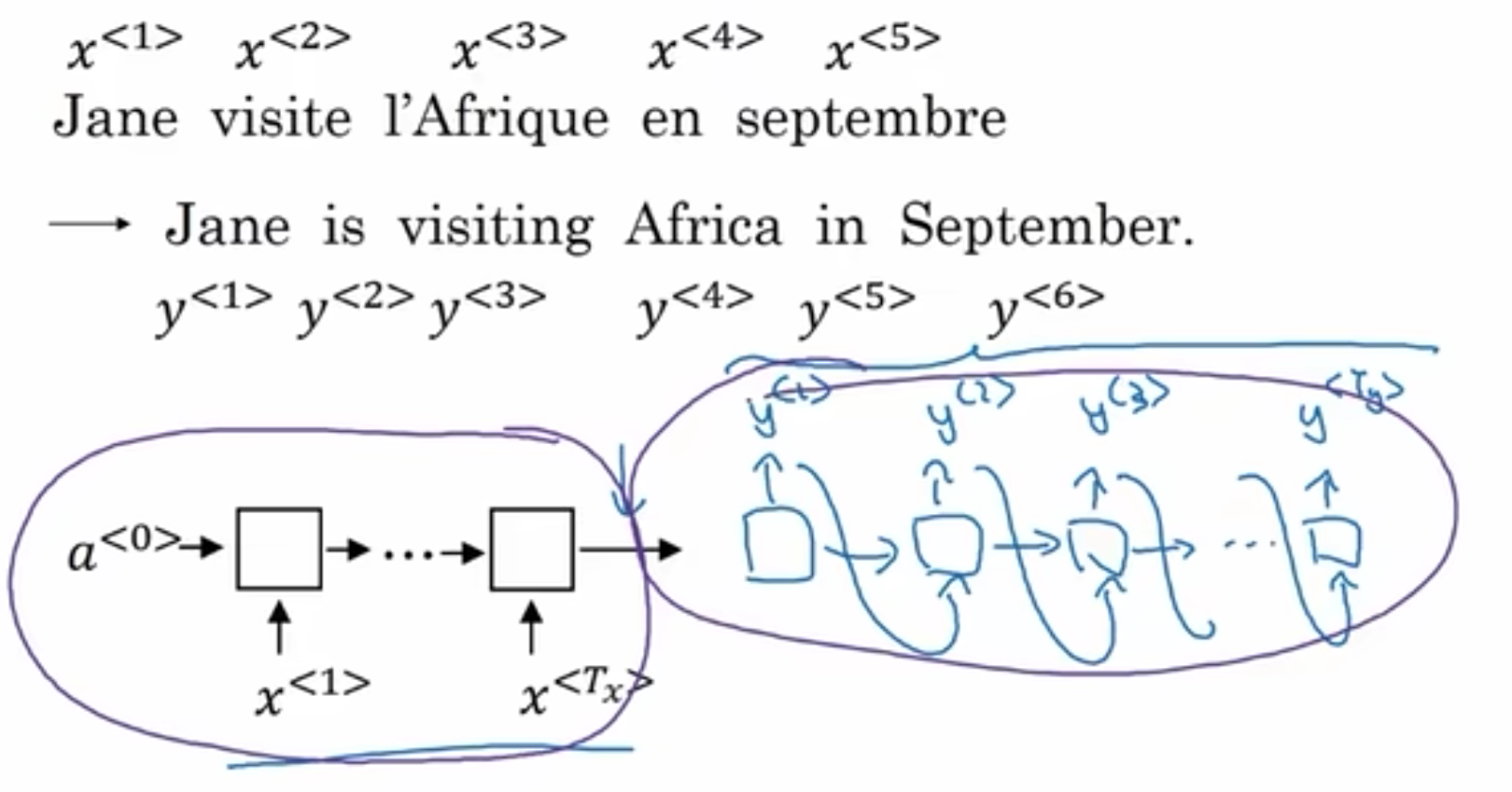
Seq2Seq模型
encoder:编码器,将输入编码成向量
decoder:解码器,将向量解码成输出
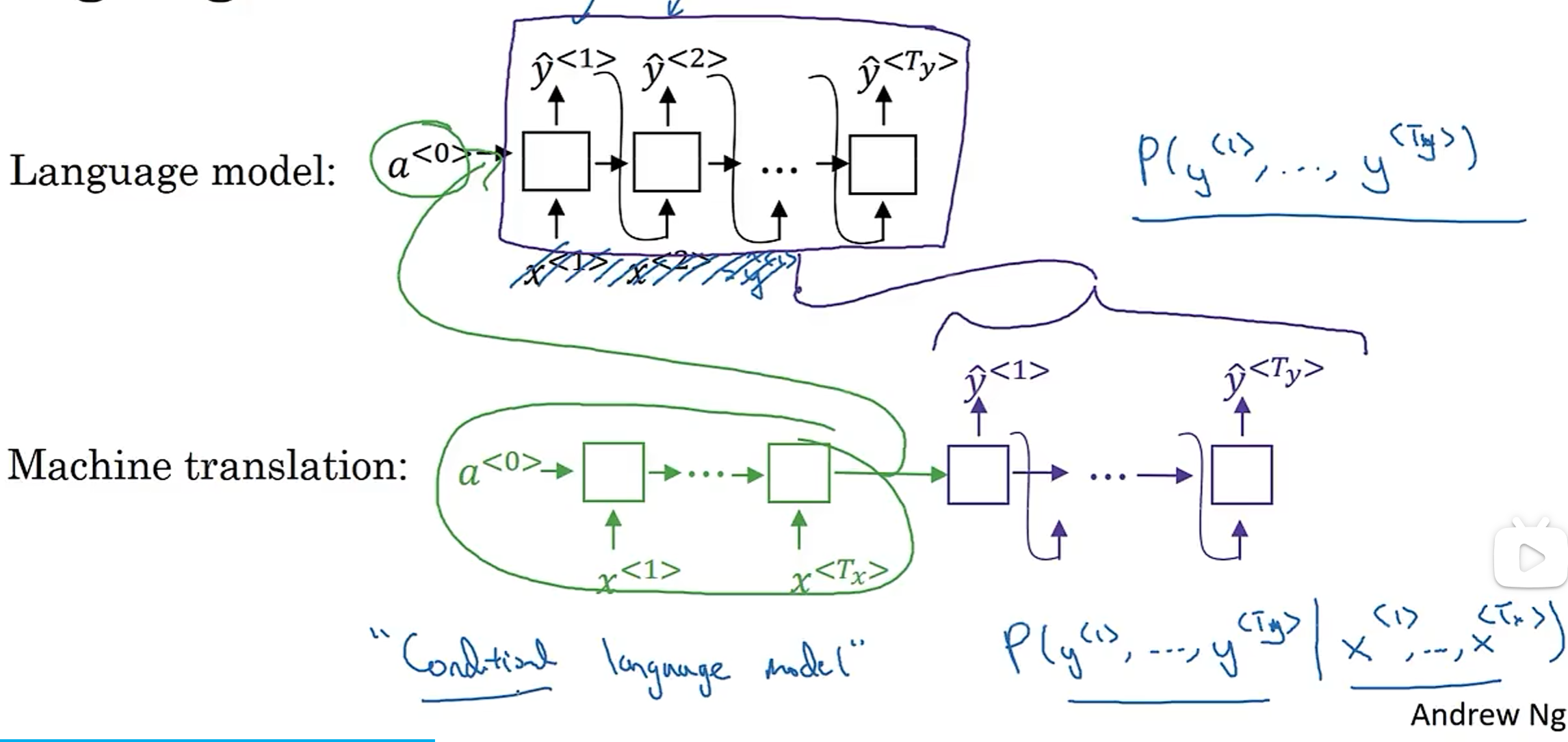
选择最有可能的句子
语言模型:输入0向量
机器翻译:输入句子
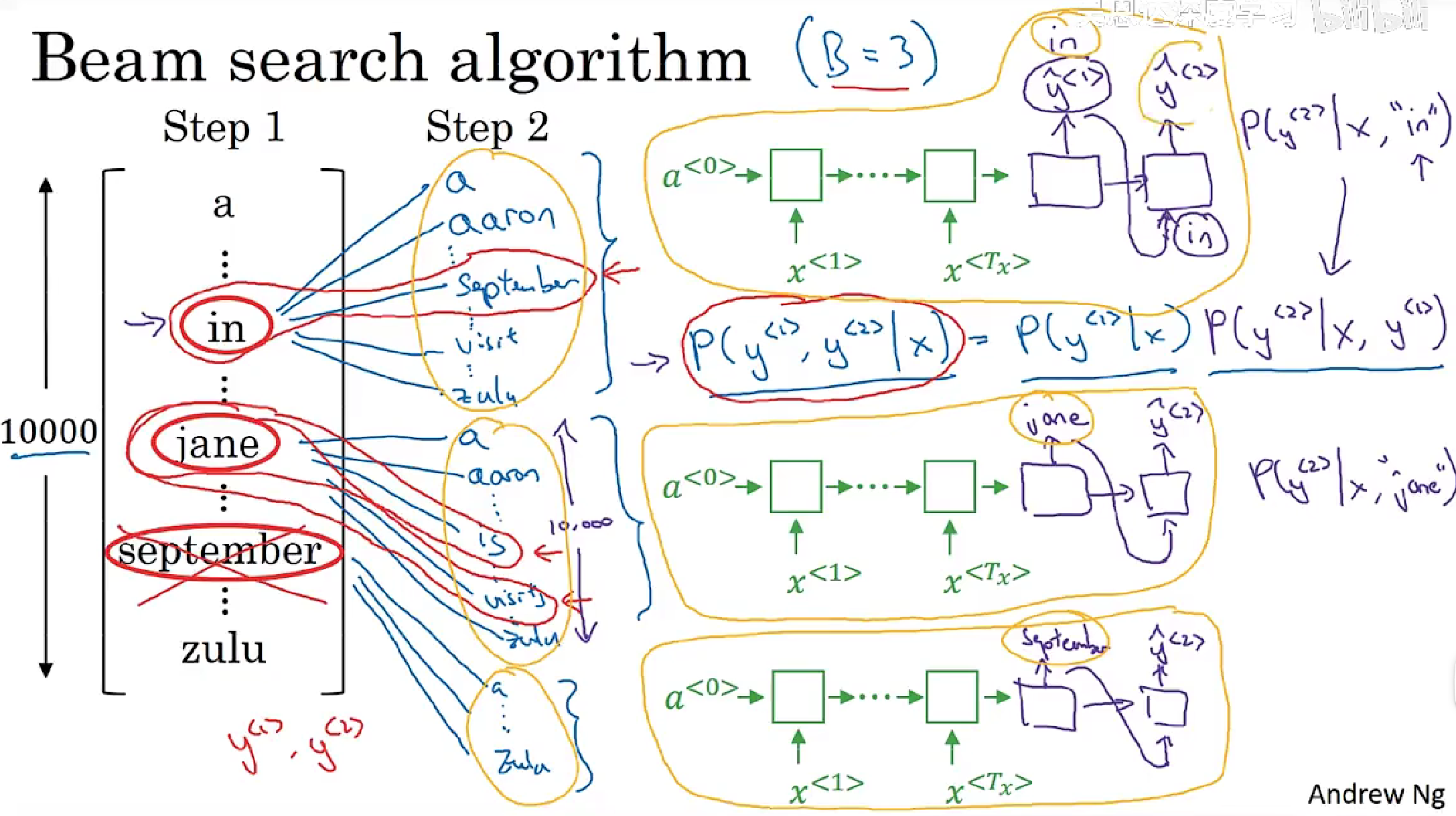
集数搜索
搜索前B个概率最大的句子
优化

Bleu分数
评估机器翻译的



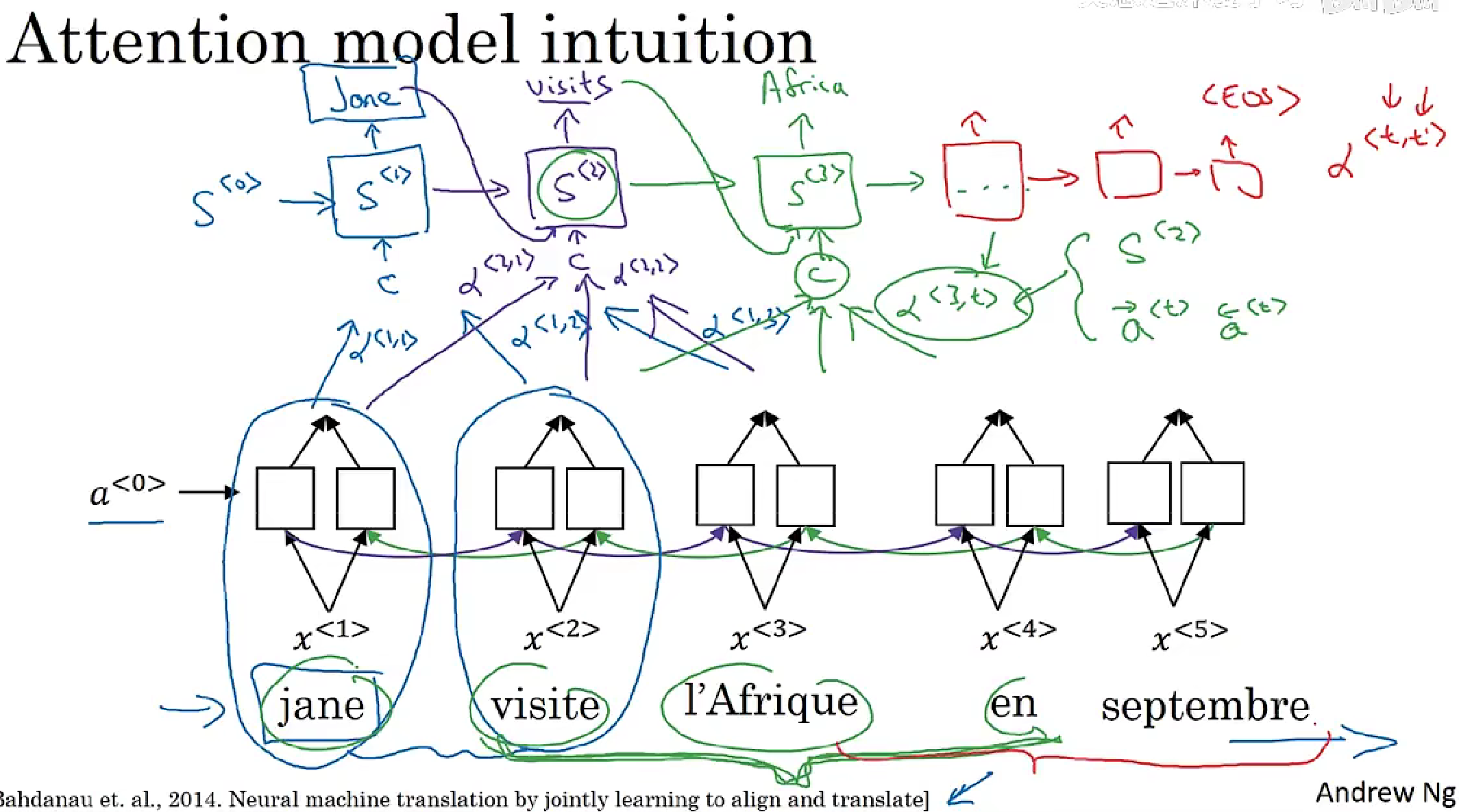
Attention
Encoder-Decoder模型的改进
直观理解
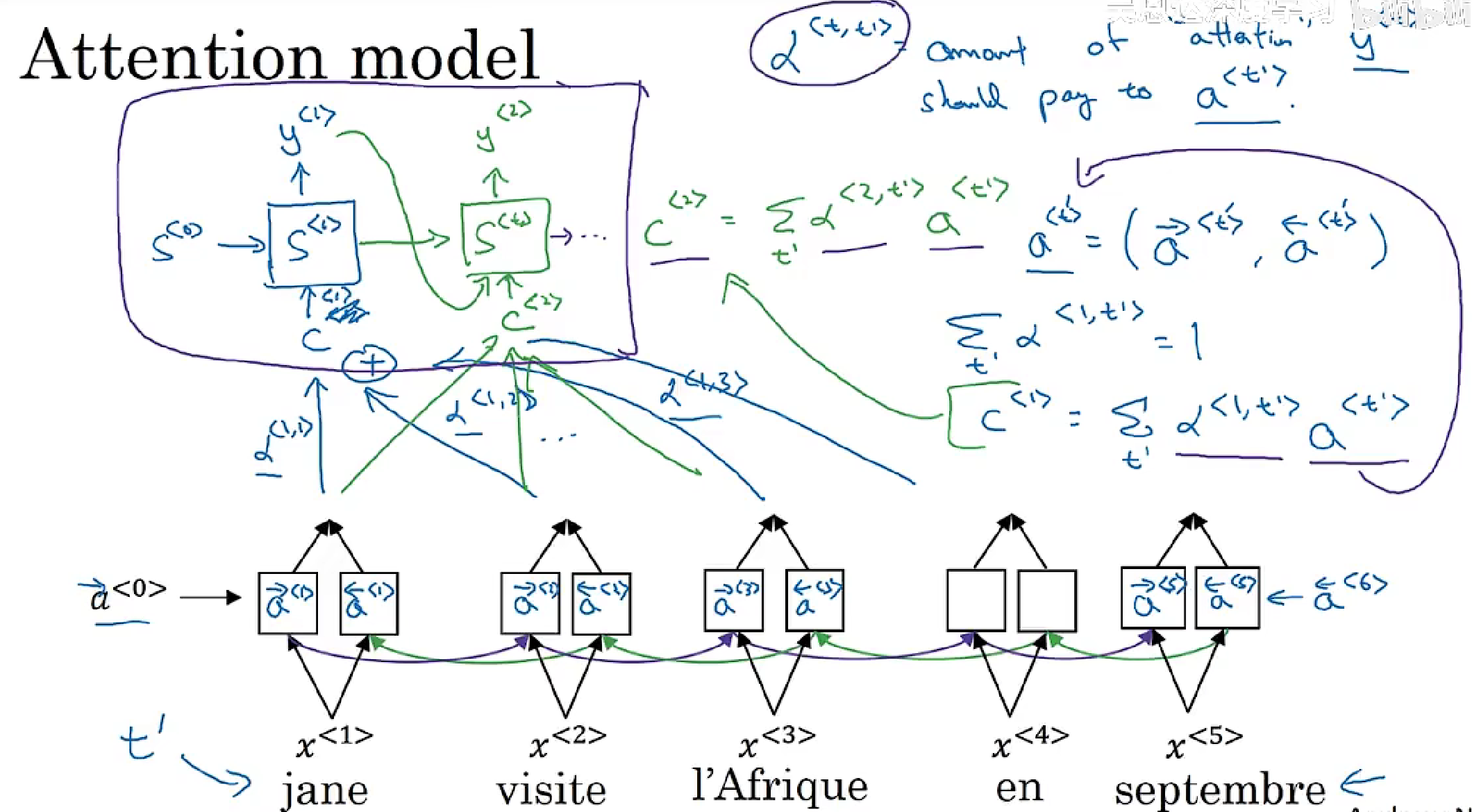
Attention模型具体
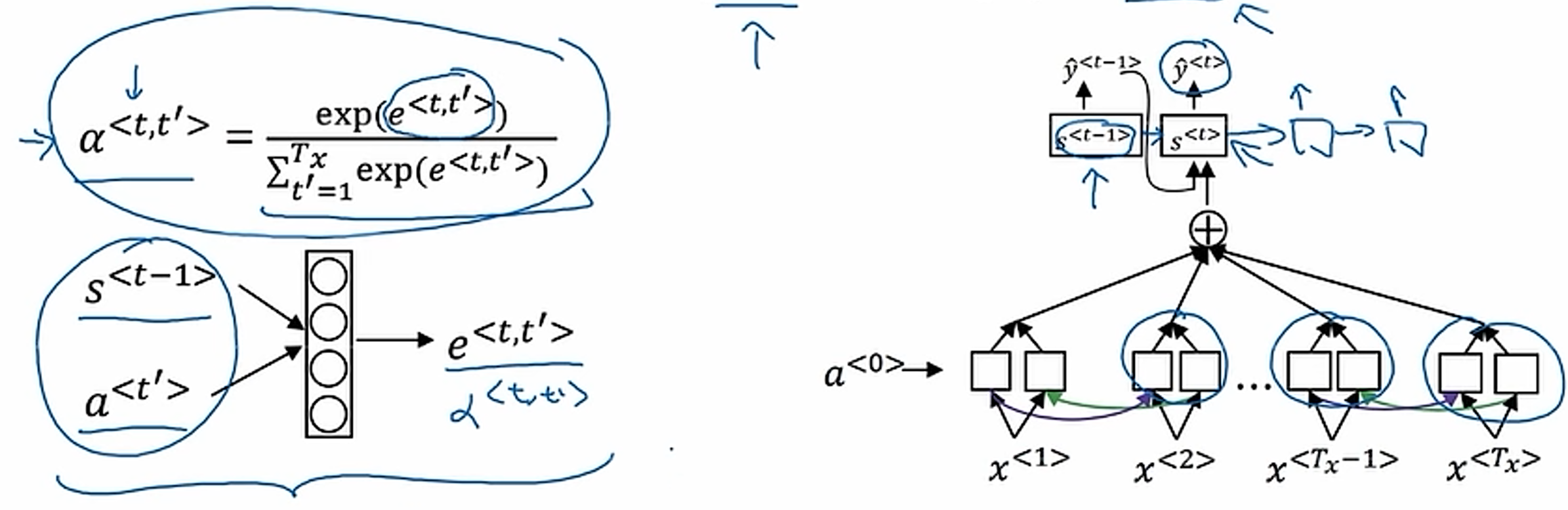
attention计算,注意力总和为1
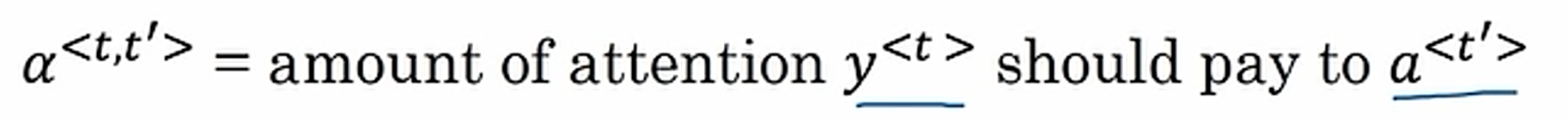
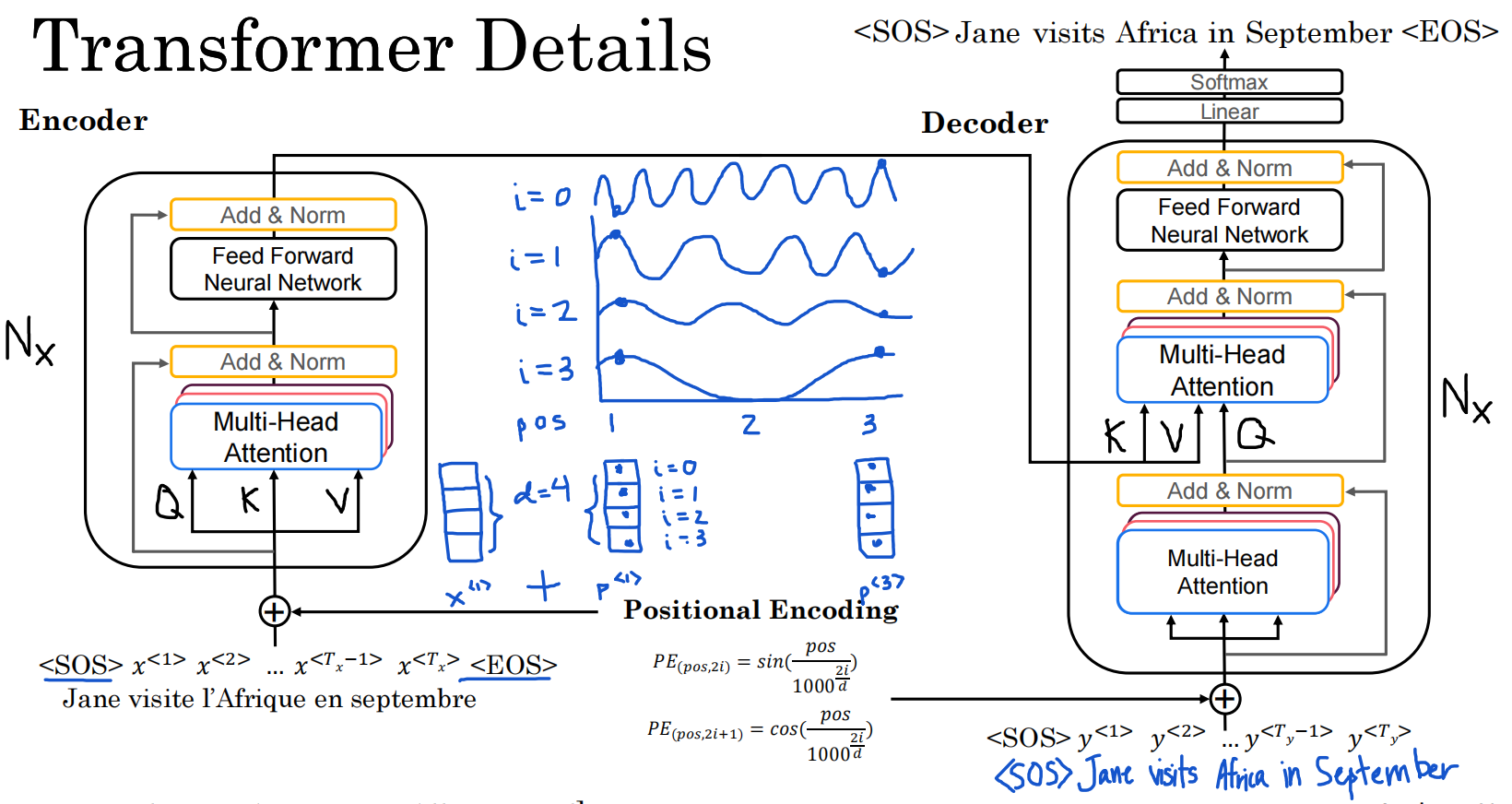
Transformer
直观理解
Attention+CNN

自注意力
不必基于词的左右内容进行调整,而是全局
A(q, K, V):基于注意力的word的向量表示

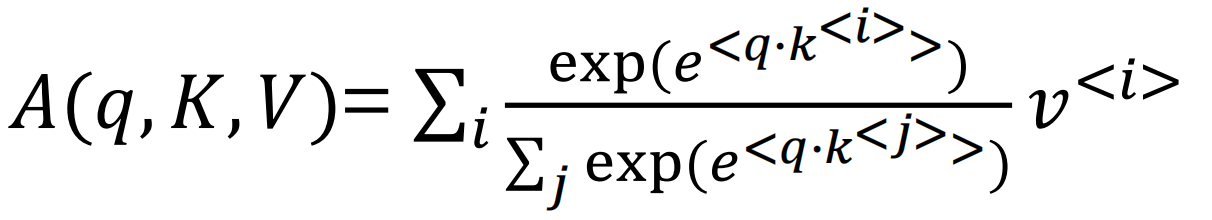
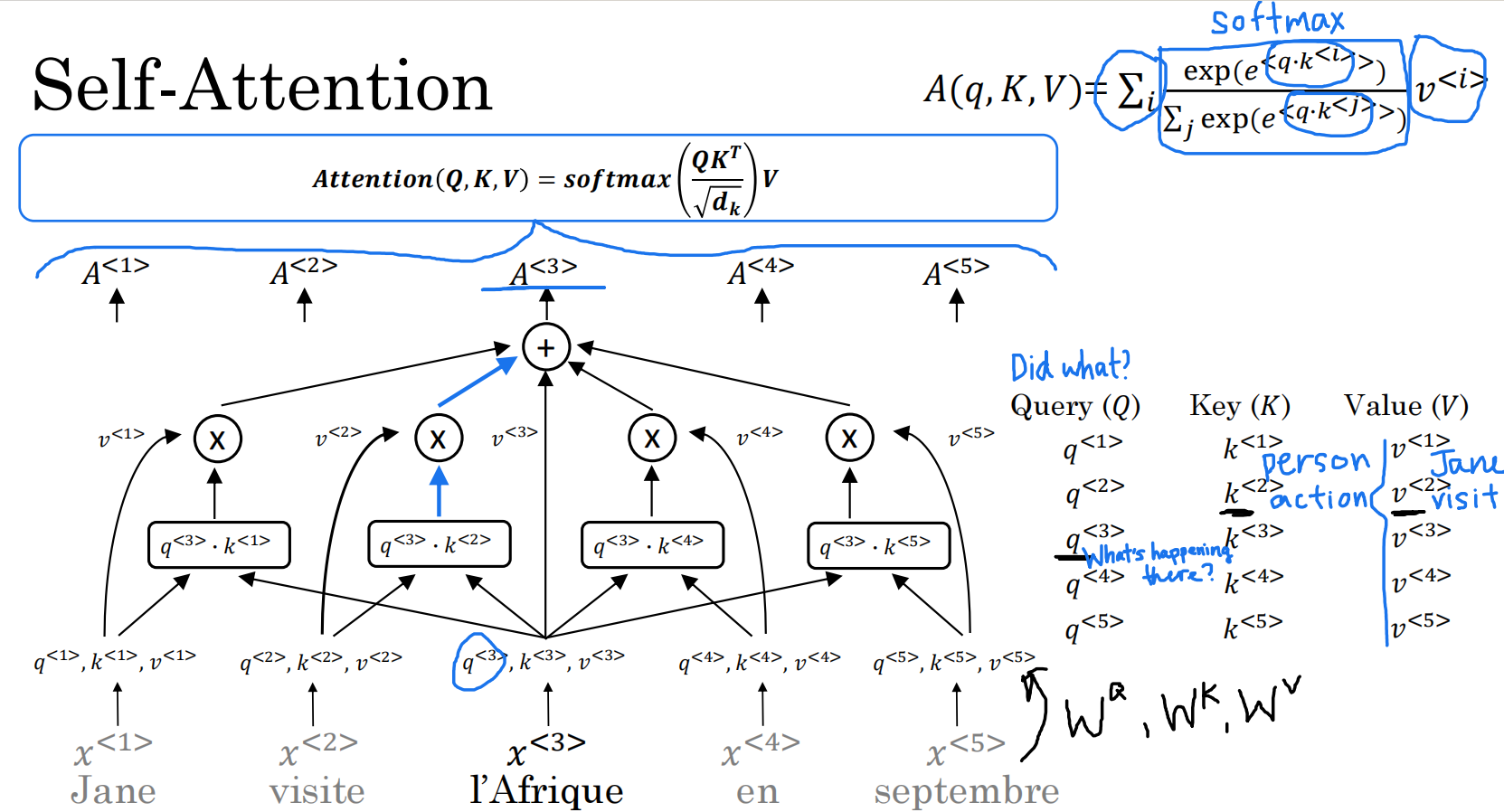
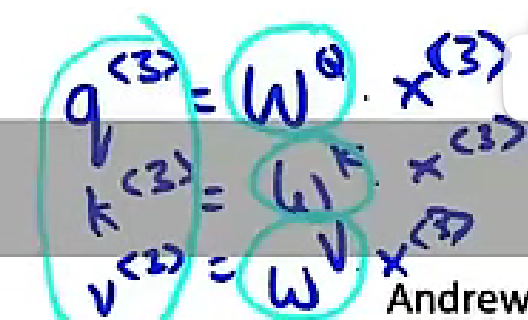
query:关于这个词的问题
key:与query点乘得出问题的答案
value:关于这个词的表述
多头注意力
需要并行计算多个头
一个头代表一个词对其他词的一个关系,多头代表一个头对其他各头的关系
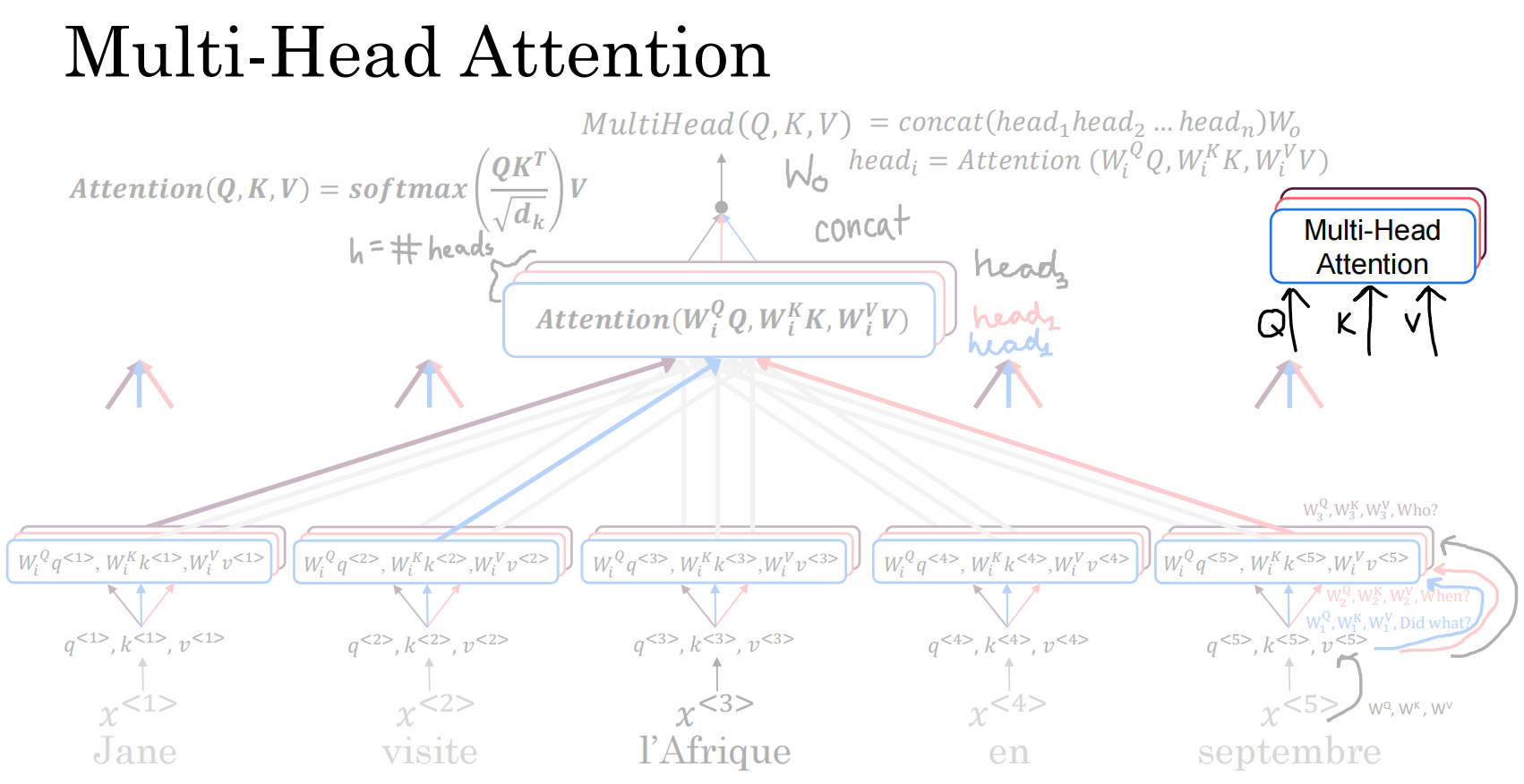
组建